|
Hello Everyone!
Welcome to the 31st edition of It Depends. Hope you are all doing well and staying safe. Today let’s talk about the second most important rule for building platform systems (Read this to learn what the most important rule is). You can read the article on the blog directly if you prefer that layout.
TL;DR
We should not have to modify central systems/platforms to achieve variant behaviours for different use cases. We should be able to plug in these behaviours from the outside to customize specific parts of the overall system behaviour. This will make our system more durable by offering a powerful mix of capability and customizability.
The Problem
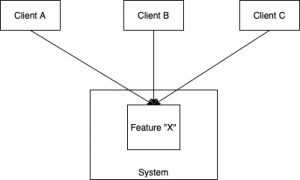
Imagine you are building a central system that is intended to be used by multiple other teams. Depending on the kind of complexity offered by the system, one or more clients may ask for variations of the original behaviour specific to their use-cases. We can readily imagine such situations arising in B2B software where every client needs some custom variant of the original feature.
How do we accommodate these situations?
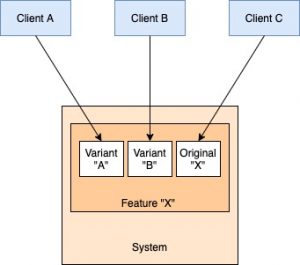
The most obvious way, of course, is to build it! The team that built the system also builds the customizations in the features as required by any client. This makes sense if these requests are rare (so the team can easily allocate time for it) or complex (this is the ONLY team that can do it). If this is not the case, however, the original team becomes a bottleneck for multiple teams because it cannot spare the time to take care of all the incoming customization requests.
The second way is to ask the client teams to get into the code base and make the changes themselves. This removes the bandwidth bottleneck. Client developers can usually make the changes given sufficient enough tools/documentation and guidance (code review etc). But over time, this almost always leads to deterioration in code quality and blurry lines of ownership. It is difficult to hold any single team accountable for the quality of the system since everyone is making changes. Depending on the nature/complexity of the change, the oversight and communication required may well be a lot. Also, this model is practically impossible if the client team is external to the organization and hence cannot be given access to the codebase.
System Boundaries are Team Boundaries
Conway’s Law, Team Topologies, and various other schools of thought have made it abundantly clear that an organization’s software architecture mirrors its communication architecture. So the problem of building customizations can be generalized to a problem of defining how client teams interact and influence the team that owns a system, thereby influencing the design of the system.
If multiple teams want to use and grow the same system, we need to define a model for coordination between them. To my mind, this model must minimally achieve two objectives:
- We should be able to evolve the software independently without getting bogged down in communication overhead. The first approach discussed above is ruled out on this ground because it puts the owning team on all change paths. Clients have to beg/bully/convince them into making the changes for them.
- We should be able to do this without degrading the quality of the codebase. The second approach discussed above is ruled out by this. Maintaining code quality and operational excellence is almost impossible if anyone can (and is expected to) make changes to your code.
So we need a way to define a system boundary and change process such that others can make changes independently without impacting our code quality. We can do this if we can allow people to “hook in” to the internal decision points of our system and modify the behaviour for their use cases. This is what Steve Yegge calls External Programmability in his legendary platforms rant (you can read my redux here) and next to Eat your own Dogfood, it is the second cardinal principle of building platforms.
External Programmability
The idea of External Programmability is to identify the parts of an application that we think should be customizable, turn them into hooks for variable functionality, and then expose these hooks externally. Clients can then plugin to these hooks and trigger custom behaviour or make decisions based on custom logic without having to go into the codebase of the system. As a result, the behaviour of the system is not completely determined by the logic implemented by the owning team, but by the collective impact of the core logic and customization hooks.
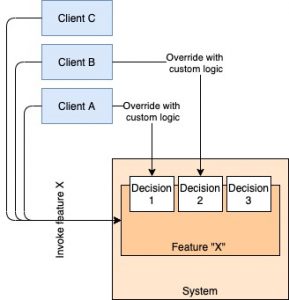
This style is, in a way, OCP at a multi-system level, and has distinct advantages over the modify-from-within approach.
- Clients know exactly how to hook in custom behaviour because the design of the system makes it explicit. No risk of them going inside the system and breaking something by mistake.
- It also makes change faster for the client, because they do not have to learn how to work inside a new codebase. They integrate from the outside along well-defined interfaces, and the customizations themselves are implemented in a technical environment of their choosing. It’s like being able to tell another microservice about which of your APIs to call at which step without having to modify its code.
External Programmability transforms an internal decision of a system into an open interface that users of the system can modify as per their needs. From a system design perspective, this means that the system interface is a lot less “closed” than you would normally expect. The internal parts which got turned into externally customizable hooks transform perhaps a suite of APIs into a collaborative interplay of decisions and actions. We are deliberately exposing a lot of system internals for customization so that we don’t have to expose the entire system to invasive change.
If we look at the traditional layered architecture style, control always flows from higher layers to lower layers. However, in the platform architecture which external programmability creates, control flow back and forth between upstream and downstream systems (client systems being considered upstream and the platform system downstream). The emergent collaborative system architecture is better visualized as a 3-dimensional mesh of systems rather than a two-dimensional stack. There are still upstream and downstream pieces but the boundaries between them are a lot more fluid.
How do we get there?
One way of implementing this is to externalize all the business logic (even the original business logic) into workflows outside the core application. The core thus becomes very, very lightweight and all the logic moves out into the orchestration layer. In this way, clients have complete control of what they want to do. They do whatever they want and then call the simplistic APIs of the core system as they see fit. This gives the ultimate freedom and inversion of control – instead of modifying what exists, clients can compose whatever they want.
The problem here is that the core that remains usually gets stripped of all business semantics and hardly remains a product at all! Clients have to build not just customizations of some existing behaviour but the entire functionality over and over again. The domain boundary completely breaks down. There is no way to know where the logic for processing a certain kind of order is implemented because that logic lives completely outside the core and we have no way of systemically finding out what is happening where.
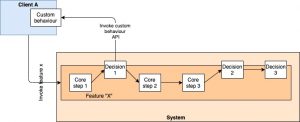
The other way is to implement a callback-based system. The original system identifies the parts which parts of the control flow it deems to be customizable (the other parts become core by definition since they cannot be modified by clients) and exposes them over APIs. The APIs allow clients to define the rules under which their specific customization should be triggered and exactly how they should be triggered (execute an API call back to the client system).
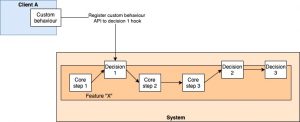
Once these customizations are “registered” with the main system, whenever client A invokes the feature X, it executes all non-overridden points as per default behaviour but executes the registered override to achieve an end-to-end result customized for client A by client A.
I have written a detailed explanation of how we can use a combination of rule systems and workflow management systems to stitch the whole experience together.
In this approach, all interactions for a certain problem come to the same central system, and we can identify from that place what we want to do. Either client uses the default behaviour of the system, or they will have registered specialized hooks to custom callbacks. In either case, it becomes easy to track down the flow of control because all branching out happens from well-known points of divergence. As a result, a porous technical domain boundary remains with much of the business logic running inside the boundary, but the occasional customization going back up the stack to client systems. Our core system is still the one place where all business logic can be traced from.
Note that in this approach, we need not distinguish between internal and external teams. All client teams communicate across a porous system boundary which defines a clear interface and protocol but otherwise, both teams operate independently. The team which owns the system and the teams that use the system are in effect co-building a much larger system by allowing each other to reach deep into each other’s systems to create business value.
From the internet this week
- Mikio Braun’s take on why we still don’t know how to create software at scale is definitely worth a read.
- This is a fascinating technical overview of how Postman handles millions of concurrent connections.
- As the Google AI Ethics fiasco continues to shake the industry and the company, here’s a scholarly take on corporate research and academic integrity.
That's it for this week folks!
Cheers!
Kislay |