|
Hello Everyone!
Hope you are doing well and staying safe. I'm trying out a new, cleaner (hopefully) look for this newsletter. Let me know what you think of it. Today we are going to look at the CQRS architecture pattern, followed by the usual awesome from the internet.
Software systems serve a variety of purposes from their first day, and the requirements on them grow over time. Changing requirements may pertain to a change in business logic, scaling needs, or some other aspects of the system.
To satisfy these often contradictory or overlapping requirements, engineers must make a variety of trade-offs in the design of the system. The problem in making trade-offs is that many of them are not required at the beginning and by the time the need arises, the system design has evolved in such a way that the trade-off cannot be made at all.
In my opinion, the most pernicious incidences of the design getting locked in happen at the data layer. A typical application’s data model is designed by marrying domain knowledge with performance considerations. The domain knowledge dictates what the entities are and how they relate to each other logically. Performance considerations dictate how they are implemented physically (e.g. RDBMS-vs-NoSQL, primary keys, indexes, etc.). These two sets of choices together enable an application to serve its use-cases efficiently.

In large applications with a lot of data and complex entity models, some implementation details become “core” over time. This is sometimes explicitly done by engineers, but often it happens in an unstated or even inadvertent manner. In these situations, new requirements can be so far at odds with the existing implementation that they cannot be accommodated at all.
This general class of problems is large with different solutions for different cases. In this article, I want to focus on problems that arise when the way data is read from an application is very different from how data is written to a system. The difference can be in terms of query patterns, output format expectations, or scale of operations.
In an earlier post, I wrote about an encounter with this situation. The order management system I was working on at that time was optimized for working with entity ids (order id, item id, etc). But over time, complex read requirements emerged which the data model was unable to support. The problems were two-fold. New query patterns were emerging which were difficult to implement efficiently in the existing implementation. Far more worryingly, the readers of order data were beginning to expect a very different model of the data. E.g. sellers on the e-commerce platform wanted their slices of a larger customer to be represented a certain way, customer-facing apps wanted the data to look very similar to how it looked in the cart.
This is not an uncommon occurrence, especially for systems that own the core entities of an organization. The data they encapsulate is so widely used that it is required to be available in many different formats. The system itself needs yet representation to work with its data.
How can we bridge this gap?
CQRS
CQRS stands for Command Query Responsibility Segregation. Systems built with the CQRS principle distinguish between data models used for Commands (write operations) and Queries (read operations). The command model is used to perform write/update operations efficiently while the query model is used for supporting the various read patterns effectively. The data between the two models is kept in sync by propagating the changes in the command model to the read model via domain events or any other mechanisms.
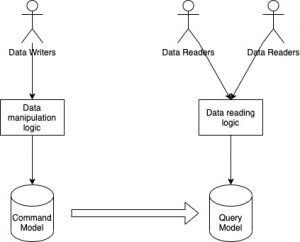
If this sounds like two different microservices to you, let me point out a subtle difference. The physical implementation of these two data models can indeed be done as two separate microservices. A single command model can even be used to support multiple query models. However, a key construct of microservice architecture is that two microservices typically represent two independent domains. In CQRS, both the command and the query models are part of the same logical domain regardless of the runtime architecture. The query model cannot function without understanding the command model deeply. The coupling here is expected, unlike the decoupled behaviour we hope to create in two separate microservices.
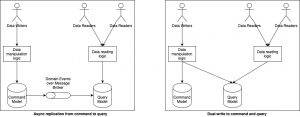
CQRS does not dictate how the two models are kept in sync. This may be done synchronously by updating both the models at the same time. It may also be done asynchronously by transmitting commands from the command model to the query model over a message broker like Kafka. The latter choice is the one made often because it creates a more scalable system, though it comes with the obvious tradeoff of eventual consistency between the write action and read action.
Isn’t this just caching?
A data mode dedicated only for reads sounds suspiciously like a cache. Indeed, the query model can be implemented using a caching technology like Redis. However, the purpose of applying CQRS is not just to separate the place where is written from the palace the data is read. The fundamental intent is to create multiply representations of the same data, each of which satisfies the needs of some users. A CQRS style may have many query schemas, each of which may use a different physical implementation. Some may use the same database, some may use Redis, etc.
Why should I use CQRS?
CQRS is a useful architecture pattern in a couple of different scenarios.
The first one is that which I have pointed out earlier in this article. If the same data model is not able to satisfy the read and write patterns of a system effectively, then it makes sense to decouple the two schemas by applying CQRS. The resulting data models can then cater to their specific requirements. CQRS effectively unlocks the data from a single representation into any number of (read) representations all of which are kept consistent with the core representation which handles all updates made to it.
The second scenario in which CQRS is helpful is in separating the read load from the write load. This may sound like cheating when I have explicitly distinguished between caching and CQRS just a couple of paragraphs above, but hear me out. CQRS doesn’t seek out caching as an objective. However, by separating the command and the query schemas, we can create the possibility of scaling one independent of the others. The query schema may live on a separate database and employ caching of its own. It may be implemented in a technology that best caters to the query patterns of a particular use case. In any of these cases, the command model is exempted from having to scale to the requirements of the query model. I would repeat here that despite all this, these are not independent systems. The coupling between them is deep and this is not a problem.
Why should I not use CQRS?
Using CQRS in a system introduces significant cognitive overhead and complexity. Instead of a single data model and technology choice, developers now have to contend with at least two data models and potentially multiple technology choices. All of this is an overhead that cannot be ignored.
The next problem is keeping the command and the query data models in sync. If the choice is made to keep the updates asynchronous, the entire system is forced to deal with the fallout of eventual consistency. This can be extremely troublesome, especially if parts of the system are directly exposed to human users who expect their actions to reflect in the data immediately. Even a single requirement for consistency can imperil the whole design.
On the other hand, if we choose to keep the model in a consistent state at all times, the CAP theorem and 2 phase commits come knocking around. If both the schemas are colocated on a single ACID-compliant database, we may still be able to use transactions to keep them consistent. However, this takes away much of the scaling benefit of CQRS. If more than one query model is to be supported, the write operations will continue to get slower and slower since they need to update all query models before they can succeed.
Both these problems make the use of CQRS a proposition that should not be taken lightly. Judiciously applied, it can result in a highly scalable application. But supporting multiple data models is a tricky affair and should only be considered if there are no other means of satisfying the necessary query patterns.
From the internet this week
- This is a great collection of resources about building internal platforms. A lot of learnings to be had.
- Once you know what to look out for, complexity and complex systems are everywhere. FOr those who do not know what to look out for, here's a primer on complexity.
- This interview with Werner Vogels touches upon a lot of the history of the architectural evolution at AWS.
That's it for this week folks!
Cheers!
Kislay |