This is part 4 in a series of posts about asynchronous programming. The previous posts are linked at the end of this article.
In the previous posts of this series on asynchronous programming, I have outlined two ways of writing asynchronous code and the underlying concepts of how this paradigm helps us achieve greater system scale than the one-thread-per-request-model. And while I have shared some caveats to using asynchronous programming in these articles, today I want to share a cautionary war story about how I and my team once got so excited about using asynchronous programming and then so shocked by the results.
About 3 years ago, we were working on Myntra’s order management system (OMS) at the time which was the source of truth for all order related information and actions in the company. It was a Java REST API based system which used MySQL as store and used the classic single-thread-per-request model. The database schema was optimized for operations on the orders primary key but over time had accumulated a bunch of indexes for facilitating reads on other columns. However, as our scale grew and grew, we realized that the myriad read patterns were overwhelming even the multiple slave databases we threw at them because the MySQl schema was too ill suited to handle them.

Thus began the quest for implementing a CQRS like architecture where the main OMS would only handle transactional operations and a read-only cache service (later name Armor because it shielded OMS from a lot of the read traffic) would store data in a format suitable for arbitrary reads. The OMS (command part of CQRS) would emit events on all data changes and the cache service (query part of CQRS) would be kept in near real time sync by ingesting these events. There were many considerations w.r.t. data management, consistency and latency but those are not relevant here. Let’s look at the technology choices instead.
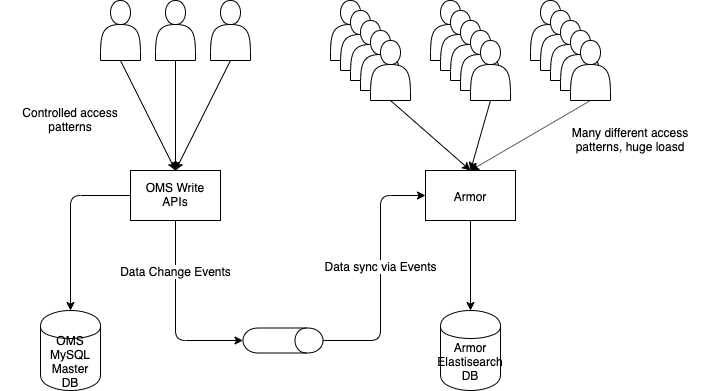
“Search at scale” is synonymous with Lucene and we chose Elasticsearch as the database for Armor. What about the service itself? Looking at the requirements, we saw that the system had two aspects:
- Ingest OMS events to keep the cache up to date
- Serve the read calls from clients.
There are many beautiful things about Elasticsearch, but at the time, one of the most appealing to us was we could use REST APIs to query it. This meant that the door to using asynchronous techniques was wide open for us!!! Lack of reactive database drivers is the most common sticking point in building end-to-end asynchronous systems, but here we were free because even our DB calls looked like REST calls. Fantastic!
If we look at the requirements in the light of this capability, we can see that most of the Armor service was going to be IO bound:
- Read from queue -> call some REST APIs for transformation -> write to ES
- Receive read call -> query from ES -> return data
I decided to use the super awesome Vert.x framework to build a completely asynchronous system. Except for data serialization and some minimal transforms, every single thing was non-blocking. And it worked beautifully. Initial launch showed that Armor could take of our entire traffic on a business-as-usual day with far less hardware that we had anticipated. So we decided to start the load tests.
Since I already said this is a cautionary tale, I will pause here a moment and let you guys form your own theories about what could have happened.
At small loads, we saw a trivial small rise in the API response times and the event consumption kept up perfectly. Data in Armor was fresh and its readers happy. Good signs. As we increased the load, however, the events were still being consumed almost immediately and the API latencies only increased minimally, but after a while the service would just freeze, often the Elasticsearch cluster would crash too. This happened every single time beyond a certain throughput. We had expected degradation, for sure, but what could be causing complete failure cliff?
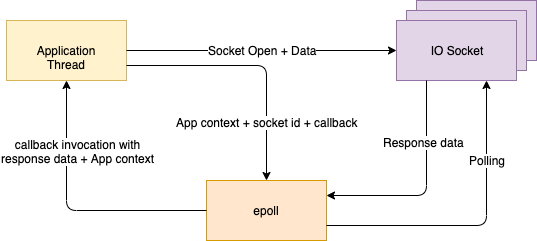
After a few dozen LOG.infos and memory dumps, a picture emerged that none of us had anticipated (no one had any true experience with asynchronous programming at scale). Let’s assume that there is only one thread in the system (there were, of course, more than one, but that only made everything that much worse). Because the whole system was asynchronous, this thread would read data from the event queue (async), call a couple more APIs (async), then call Elasticsearch (async) to write the data.
QueueReader.readMeassage()
.onSuccess(msg -> {
SomeServiceClient.getData()
.onSuccess (someResponse -> {
SomeOtherServiceClient.getData()
.onSuccess(someOtherResponse -> {
JsonObject finalPayload = someMinorDataMassaging();
ElasticsearchClient.writeData(finalPayload)
.onSuccess(response -> LOGGER.info(“Success”));
})
})
});The asynchrony means that the thread never really stopped anywhere and ended up reading events from the queue as fast as it possibly could (unless interrupted by some IO completion). This in turn generated such a flood of concurrent requests to the other APIs and to Elasticsearch that they froze or collapsed under the load. But Armor did’t know about this (remember asynchronous) so it still kept picking up messages and trying to do its thing. The non-responsiveness of downstream systems, though, meant that the in-memory stash of call stacks of unfinished requests would now increase steeply in Armor, quickly leading to memory exhaustion and unresponsiveness. We had thought that even if downstream system fail for any reason, setting proper timeouts and circuit breaker would protect Armor (protecting armor — ironical. I know.) but we found that under load, Armor created unfinished requests in its memory much, MUCH faster than what timeouts could shed.
Once we determined the behaviour of the system, the way out was straight-forward. Concurrent requests were killing the system, so we put a limit on the number of open requests that the system could have. This is the classic throttling pattern, where a counter was incremented when a request was started and decremented when it was completed. If the counter was already at max value, the thread trying to make the request would be forced to sleep for some time and try again later. This immediately call flood, and now we began to see more controlled flow of data change events through the system — we could change the value of the counter up or down to adjust our throughput based on what the downstream systems could handle.
So what is the moral of the story ? For me, it is that asynchronous programming is such a paradigm shift in system architecture that it should be analyzed very different from “synchronous” system. We analyzed response times but never thought how many concurrent requests there would be at any point because in a synchronous system, the calling system is itself limited in how many concurrent calls it can generate, because of threads getting blocked for every request. This is not true for asynchronous systems, and hence a different mental model is required to understand causes and outcomes.
Any large software system (especially in the current environment of dependent microservices) is essentially a data flow pipeline and any attempt to scale which does not expand the most bottlenecked part of the pipeline is useless in increasing data flow. We thought of pushing a huge amount of data through our pipeline by making Armor alone asynchronous and failed to distinguish between a matter of Speed (doing this faster) from a matter of Volume (doing a lot of it at the same time). The latter is what asynchronous programming is all about — it works better than the blocking code model because instead of getting stuck at pending IO, it “enqueues” it for deferred, interrupt driven processing. Asynchronous programs should be always be analyzed in terms of queuing theory.
A formal statement of this is Little’s Law, which explicitly distinguishes between throughput and capacity.
At steady state, the average number of items in a queuing system equals the average rate at which items arrive multiplied by the average time that an item spends in the system.
In subsequent posts, we will look at Little’s law, throughput, capacity, and throttling/backpressure as they pertain to asynchronous programming when visualized as stream processing.
A big shout out to my partners in crime on this escapade — Navneet Agarwal, Sanjay Yadav, Rahul Kaura, Neophy Bishnoi, and all the rest of the Myntra order management team.
These are the previous posts of this series.


One thought on “Asynchronous Programming : A Cautionary tale”