This is a deep dive into using Rulette for modelling business rules. It is a simplified (slightly) version of a real world use case that I have used Rulette for in production. We will try to model the tax that must be paid when certain types of items are sold by manufacturers located in different states.
In the beginning…
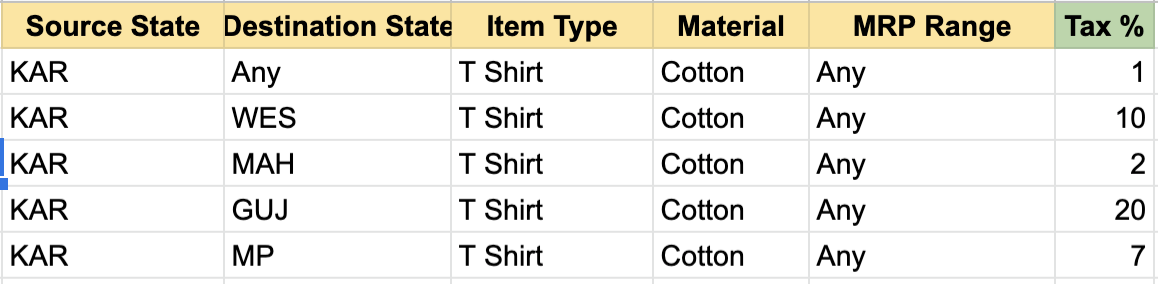
It starts with the forging of the great tax laws, where the government mandates that the tax that must be paid by a manufacturer on a sale depends on the state in which his facility is located (West bengal, Punjab…), the type of the item (T-shirt, shoes, bags etc), the material (silk, leather, gold…) and the price of the product. The product managers confers with the financial and legal team and puts together all combinations of these attributes in an excel sheet. The whole thing is a layered structure built on default rules with more specific rules applied on top of them (Karnataka charges 5% on shoe sales, unless they are made of leather and priced above Rs. 5000, in which case it charges 10%). Something like this.

The dev team has to build a system to store these rules and determine what should be the applicable taxes on a sale. There are a lot of rules, so the system should be able to handle that, but the expectation is that they will be changed infrequently but read very regularly. Of course, we would like to make the management of all these rules as easy as possible and their evaluation as fast as possible. Let’s say we already have a Java base tax system and we want to enhance that to handle the new tax regime. With this, let’s jump into the solution(s).
Hard-coded If-else
Any set of rules can be expressed as a combination of if-else conditions – that’s what all rule management is. So the naive way would be to hardcode all of these rules and return the corresponding tax values as the output. If there is a particular dimension we don’t care about in a rule (e.g. Any MRP), we will represent it with the string “Any”.
public String getTax(
String sourceSate,
String itemType,
String material,
Double mrp) {
if (sourceState == "KAR" && itemType = "bag" && material="Any" && mrp ="Any") {
return "5";
} else if (sourceState == "KAR" && itemType == "bag" && material=="Leather" && mrp > 5000) {
return "10";
} else if........//About 100000 more time
} else {
return null;
}
}This will work, but it will turn the codebase into the perfect hell for man and beast. This is difficult to understand, change and test for correctness. If anyone asks for tax rules in our system, there is no way but to open code – which makes conversations with product managers and business teams very difficult. They have no visibility into the technical representation of the rules. Additionally, from a computing perspective, this is a brute force lookup when trying to evaluate any outcome. We are iterating over all combination of all the inputs. The structure of the problem indicates that this could be improved if we were to use some tree/graph based solution.
Configurable if-else
A huge step up from this situation would be to capture the rule inputs and the operators (equals, greater than etc) in some sort of configuration or DSL which we can parse at start-up to build the entire set of if-else combinations. This will make it easy to manage and share the rules outside of code because we can transform the product managers excel sheet into the configuration independently and then reload them into the tax system. The make the code look simpler, the heavy lifting has moved from implementing the code to implementing the transformation of excel sheet to DSL.This does not remove the computational complexity – we still evaluate all combinations to find out which rules apply, the combinations are just generated using config.
public String getTax(
String sourceSate,
String itemType,
String material,
Double mrp) {
List<Config> allConfigs = loadCOnfigs(file);//Assuming things are stored in a file
for (Config config : allConfigs) {
if (config.matches(sourceState, itemType, material, mrp)) {
return config.output;
}
}
return null;
}Rulette for modelling rules
Rulette encompasses the learnings for the previous two attempts and presents them in a single, compact solution.
We see that the most intuitive configuration/DSL to model the rules is the same format in which they were shared – a 2D matrix with each column representing a “rule input” (source state, item type, material, price) and each row representing a “rule”, i.e a combination of these inputs mapped against an output value.
We also see that the relation between column of the sheet (in a single row) is of “AND” type (also seen in the code above) and that any “OR” relationships are modelled as mutltiple rows (as shown by the else-if conditions in the code above).
Rulette carries over these modelling insights into the heart of the application so that the dev and business teams are talking in the same language when it comes to rule modelling.
Setting up Rulette
Let’s assume that we take the excel sheet and dump it into a MySQL table called ‘tax_rule_system‘ in ‘tax‘ schema. You don’t necessarily have to do this (Rulette has an extensible data loading model which allows you to plug in any source of rules), but MySQL is officially supported out-of-the-box so we will use that in this case case study. This table is near identical to the excel sheet, and now contains all our tax rules.
CREATE TABLE `tax_rule_system` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`source_state` varchar(100) NULL,
`item_type` int NULL,
`material` varchar(100) NULL,
`min_mrp` DECIMAL(12,3) NULL,
`max_mrp` DECIMAL(12,3) NULL,
`rule_output_id` VARCHAR(256) NOT NULL,
PRIMARY KEY (`id`)
);Let’s create two metadata tables in the ‘tax’ schema (or any other schema the tax application has read access to). These tables help Rulette in making sense of the tax rules we stored earlier.
CREATE TABLE rule_system (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`table_name` varchar(100) NOT NULL,
`output_column_name` varchar(256) DEFAULT NULL,
`unique_id_column_name` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `rule_input` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL,
`rule_system_id` int(11) NOT NULL,
`priority` int(11) NOT NULL,
`rule_type` varchar(45) NOT NULL,
`data_type` varchar(45) NOT NULL,
`range_lower_bound_field_name` varchar(256) NULL,
`range_upper_bound_field_name` varchar(256) NULL,
PRIMARY KEY (`id`)
);The first table models the rule system as an entity and allows us to locate where the rules of a rule system are stored. In this example, we can perform the following mapping to map a rule system name “tax_rule_system” to the data stored in our ‘tax_rule_system’ table. It also identifies that that unique identifier for rules in that table is called “id” (the primary key) and that the output tax values live in the column named “rule_output_id”.
INSERT INTO rule_system
(`name`, `table_name`, `output_column_name`, `unique_id_column_name`)
VALUES
('tax_rule_system', 'tax.tax_rule_system', 'rule_output_id', 'id');The second table interprets the columns of our rule system. Each row in this table defines the name of the input (source state, material, item type, mrp), its type (VALUE or RANGE), its data types (String/Number/Date), its priority (the order in which inputs are matched during evaluation). You can learn more about types and data types here and about how rule evaluation happens in Rulette here.
For now, just focus on the priorities being set for each input and the since the MRP value is a RANGE input, it is physically stored as two columns (‘min_mrp’, ‘max_mrp’) in the ‘tax_rule_system’ table which are mapped as the `range_lower_bound_field_name` and `range_upper_bound_field_name` columns in the last INSERT statement.
INSERT INTO rule_input
(`name`, `rule_system_id`, `priority`, `rule_type`, `data_type`, `range_lower_bound_field_name`, `range_upper_bound_field_name`)
VALUES
('source_state', 1, 1, 'VALUE', 'STRING', NULL, NULL);
INSERT INTO rule_input
(`name`, `rule_system_id`, `priority`, `rule_type`, `data_type`, `range_lower_bound_field_name`, `range_upper_bound_field_name`)
VALUES
('item_type', 1, 2, 'VALUE', 'NUMBER', NULL, NULL);
INSERT INTO rule_input
(`name`, `rule_system_id`, `priority`, `rule_type`, `data_type`, `range_lower_bound_field_name`, `range_upper_bound_field_name`)
VALUES
('material', 1, 3, 'VALUE', 'STRING', NULL, NULL);
INSERT INTO rule_input
(`name`, `rule_system_id`, `priority`, `rule_type`, `data_type`, `range_lower_bound_field_name`, `range_upper_bound_field_name`)
VALUES
('mrp_threshold', 1, 4, 'RANGE', 'NUMBER', 'min_mrp', 'max_mrp');
All of this setup is included in the sample SQL script in the Rulette examples module. It also contains a bunch of sample rules which you can insert into the tax_rule_system table to play around with this case study.
That’s it! Rulette is now set up for use. Let’s look at the code side now.
Using Rulette in code
The first step is to add Rulette library to our tax system. In Maven, we can do this:
<dependency>
<groupId>com.github.kislayverma.rulette</groupId>
<artifactId>rulette-engine</artifactId>
<version>1.3.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.github.kislayverma.rulette</groupId>
<artifactId>rulette-mysql-provider</artifactId>
<version>1.3.2</version>
<scope>compile</scope>
</dependency>
The first is the dependency is for the Rulette evaluation engine, and the second is for MySQL data loading plugin which we will use to connect with the database setup we just did.
Now we need to tell Rulette how to connect to the database. Rulette into uses Hikari connection pool which tis highly configurable. For this, create a properties file where it can be found and loaded by your application. A sample file looks like this.
Now we can initialize the tax rule system as follows:
File f = new File("db properties file path");
IDataProvider dataProvider = new MysqlDataProvider(f.getPath());
RuleSystem rs = new RuleSystem('tax_rule_system', dataProvider);This will first load the rule system definitions from our meta-data tables, and then load all the rules for the “tax_rule_system” in the memory in a trie format optimized for evaluation. Make sure that you instantiate each rule only once because each new RuleSystem object contains all the rules from the database in memory. If you mistakenly start instantiating a new object for every evaluation request, you will quickly run out memory!
We are now ready to start evaluating rules.
Let’s say we need to know what tax tax rate is applicable generally in the state of Karnataka. We can do the following.
Map<String, String> inputMap = new HashMap<>();
inputMap.put("source_state", "KAR");
Rule applicableRule = rs.getRule(inputMap);
if (applicableRule != null) {
System.out.println(applicableRule);
} else {
System.out.println("No rule found");
}What about finding out how items made of leather are taxed in the state of Karnataka?
Map<String, String> inputMap = new HashMap<>();
inputMap.put("source_state", "KAR");
inputMap.put("material", "leather");
Rule applicableRule = rs.getRule(inputMap);
if (applicableRule != null) {
System.out.println(applicableRule);
} else {
System.out.println("No rule found"); }Note that the values of the map should exactly match the values of the database, so in an actual application you might be doing some data normalization before invoking the getRule method. Putting it all together, here is what the new code in the tax system might look like:
public class RuletteBasedTaxManager {
private final RuleSystem taxRuleSystem;
public RuletteBasedTaxManager(String dpPropertiesFilePath, String ruleSystemName) {
File f = new File(dpPropertiesFilePath);
IDataProvider dataProvider = new MysqlDataProvider(f.getPath());
taxRuleSystem = new RuleSystem(ruleSystemName, dataProvider);
}
public Optional<String> getTax(Map<String, String> inputMap) {
Rule applicableRule = rs.getRule(inputMap);
if (applicableRule != null) {
return Optional.ofNullable(applicableRule.getColumnData(rs.getOutputColumnName()));
} else {
return Optional.empty();
}
}
}Notice the syntax of how the output of the applicable rule is being accessed. As a library, Rulette does not understand what the output value “means in any use-case – it simply returns the best matching rule. This business-agnosticism can be used to build another level of indirection where we do not store the actual tax value inside the tax_rule_system table but rather a reference to an external data source somewhere else. This can be useful in case we have already some data in our system and we need a rule system to map different use-cases to them. The Rulette part will continue to work in exactly the same way while the using application can now use the returned output as a reference in other systems.
This compact piece of code shown above all the complexity of modelling the business rules and evaluating input data against it in a blazingly fast manner. Using Rulette also means that you can talk to the business teams in their own language (anyone can understand the tax_rule_system table) and that you can add more rules without having to change you code.
More of the ways in which Rulette can be used to manipulate MySQL based rules are outlined in the examples module.
This case study demonstrates how to model business rules using Rulette. But we all know that rules never stop evolving. In the next post we will see how we can easily evolve this rule system to incorporate changes to the tax regime.