In my previous post, I described strategies for improving thread utilization in an IO-heavy environment. I will take a closer look at the thread-based asynchronous programming approach in this post. Whenever I say “blocked thread” in this discussion, I mean threads blocked/waiting on IO. This is the waste we are trying to get rid of — threads blocked on the CPU can only be unblocked by addition of more hardware. This strategy allows us to achieve massive system scale even when working with blocking code.
What is thread-based asynchronous programming
The thread-based asynchronous programming approach, also called “work-stealing” or “bulkheading”, allows one thread pool to hand over a task to another thread pool (let’s call it a work thread pool) and be notified to handle the result when the worker thread pool is done with the task.
From the perspective of the calling thread, the system now becomes asynchronous as all of its work on a single call path is not being done sequentially — it does something, then hands over IO related tasks to one or more worker pool, and then comes back to resume execution from that point onwards (having done some completely independent task in between).
Threads on the worker pool still gets blocked for IO, but now only the threads of this pool get blocked, thereby limiting the cost to the system. Other code paths of the system which do not involve IO activity are scaled-up by the freed caller thread. System throughput increases considerably because the calling thread doesn’t sit around waiting for IO to complete — it can perform other computations.

A good analogy for understanding this behaviour is that of a checkout counter in a shopping mall. A small number of checkout counters are able to handle a large mall of visitors so long as not every one comes for checkout at the same time. Only a small number of workers (those at the checkout counter) are blocked on the checkout function — other workers are free to assist shoppers. How many shoppers could be accommodated in the mall if a worker had to be attached to a shopper from the moment they entered the mall till checkout?
A more technical analogy is that of a connection pool, e.g. database connection pool or TCP connection pool. In a service, we could have all threads that want to call another service create their own RPC connections (let’s ignore the connection creation cost) and fire their own API calls. However, so long as not all threads need to access the other service at the same time (i.e. there are other things the system has to do), we can create a small worker pool of RPC connection and funnel all API calls through them and free the calling threads of this blockage. By multiplexing the calls over this small thread pool, we can free up a lot of other threads more doing non-IO related work. This is exactly what happens when we use Apache Async HTTP client or others of its ilk.
Handling task completion
We have so far spoken about off-loading of work to worker threads. The other equally important aspect of the asynchronous model is the interrupt-based program execution pattern. Having offloaded its task to a worker thread, the calling thread needs to know where it was in its call path when it receives the result of the task from the worker. But tracking runtime state is a problem. Where is it to be kept and how?
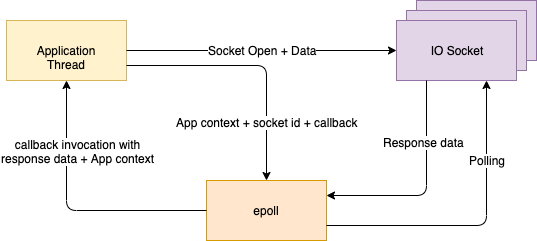
This problem is typically solved by introducing callbacks or callback handlers which are methods to be invoked by the worker thread on completion of the task given to it. The calling thread registers these callbacks to the Future returned by the worker pool and the language/framework can now easily track and invoke them on the calling thread by issuing an interrupt to it (to get it to stop whatever it was doing) and instructing it to execute the relevant callback. The handoff look something like this:
Thread 1 calls worker pool to give it a task.Thread 2 in worker pool executes the task and invoke callback.Thread 1 gets an interrupts and switches to executing the callbackDifferent languages give different callback provisions, but variants of onComplete and onFailure are the most common. As the name suggests, these are invoked on success and failure of the task given to the worker pool.
Coding Time!
To make things clearer, let us look at some (pseudo) code in Java. In the one-thread-per-request model, an HTTP API call to external service might look like this.
public class Client {
public Response get(String url, Request request) {
// API calling logic
}
}public class CallingClass {
private Client client = new Client(); public void call() {
String url = “some-api-url”;
Request requestData = new RequestData(); Response response = client.get(url, requestData);
LOG.info(“Got data {}”, response);
}
}The thread running this the CallingClass code will invoke the API via the client, then wait for the response to come back from the remote server so that it can unmarshal it to the response object. It would then log it and go on executing further instructions. All very familiar.
In the work-stealing style, the client contains an internal thread pool to which all requests are submitted. ExecutorService is the recommended way in Java though you can, of course, hand roll your own. The caller thread is returned a Future (check out the differences between futures and promises elsewhere – deliciously confusing!) which indicates that a task will be done in the future and the caller notified.
Threads of the client pool now execute the call with same blocking behaviour but hidden from the caller thread, which has, in the meanwhile, go on to serving some other request. When the response object is ready in the client or the call is known to have failed, the Future is completed and the calling thread interrupted to execute completion/failure handlers of the Future.
public class AsyncClient {
// Create thread pool of size 5 with task timeout of 300 ms
private ExecutorService workerPool = new ThreadPoolExecutor(5, 5, 300, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(10)); // The task to handover to the work pool
private class ApiCallable implements Callable<Response> {
private String url;
private Request request;
public ApiCallable(String url, Request request) {
this.url = url;
this.request = request
}
@Override
public String call() throws Exception {
// API calling logic
}
} public Future<Response> get(String url, Request request) {
return workerPool.submit(new ApiCallable(url, request));
}
}public class CallingClass {
private AsyncClient client = new AsyncClient(); public void call() {
String url = “some-api-url”;
Request requestData = new RequestData(); Future<Response> responseFuture = client.get(url, requestData);
responseFuture.onComplete() {
// callback handler for successful future completion
LOG.info(“Success with data {}”, response);
}.onFailure() {
// callback handler for future completion failure
LOG.error(“API call failed with response {}”, response);
} LOG.info(“Moving on immediately”);
}
}This code will log “Moving on immediately” before any of the other log messages, and if we log the thread name inside the callback handlers and inside the call() method of AsyncClient, we will see that they are being executed on different threads.
Any number of threads can execute the calling class code, but as long as the AsyncClient can complete a given task in less than 300 ms, they will all remain free to do other things while their Future is not completed. This is how asynchronous programming helps us achieve massive system scale.
Let’s do this, then?
Inspite of the massive scale systems designed with dedicated thread pool can handle, there are a few problems that we need to be aware of before jumping onto thread-based asynchrony with both feet. Some are practical problems related to code writing and maintenance, others are somewhat more philosophical.
That code looks weird!
To most programmers weaned on old-school Java programming, this callback style of coding smells like Javascript, and so Evil by definition. This code can get seriously complicated to understand and debug once you have a few parallel or serial task handoffs happening to create nested callbacks (aka callback hell). This is one of the biggest problems in all asynchronous programming in any language.
Another smaller problem (in Java-ville, at least) is that ThreadLocal variables no longer work. Since the calling thread hands off the work to another thread and moves to other tasks, any context stored as a ThreadLocal (think request context in many services) is lost. The only way to propagate it is to explicitly pass it along as a parameter in the task handoff, which often results in ungainly APIs that accept an explicit yet opaque “context” parameter.e.g. Instead of the neat
Future<Response> response = client.get(url, request);we get this, where it isn’t clear what the context has to do with anything.
Future<Response> response = client.get(context, url, request);Did we really change anything?
Going back to the shopping mall/connection pool analogy. there are two behaviours worth noticing:
- Members of a worker pool are committed to a specific task/set of tasks — even if no shoppers buy anything, the checkout counters still have to be manned. or if we add a caching layer upstream resulting in fewer DB queries, the DB connection pool would still be maintained.
- Size of a pool is determined not only by the amount of work it needs to do, but also by the nature of the work. e.g. If all shoppers start coming to the checkout counters quickly, more workers would be needed to handle them.
These behaviours point us towards the main drawback of the work stealing approach — the size of each worker pool has to be continuously tweaked manually as the operating environment of the system changes(scale, new tasks, modified older tasks etc). The throughput of a system built using thread pools can be deterministically computed only if the nature of the game remains exactly the same. We have to constantly monitor if the nature and volume of tasks allocated to each worker pool are changing, and if so, what should be the new thread allocation.
This need for constant supervision leads us to a still deeper insight — we have not changed the fundamental programming model at all!!! The calling thread is merely pretending to be unblocked but essentially its block has been pushed across to some other thread. IO is still blocking and threads are still needed for each IO task — even though our original problem statement was to remedy this very thing.
Work stealing gives us significant improvements in system scale and resilience towards runtime fluctuations, but it is focussed on isolating and containing the problem of thread-blocking. It does not remove the root cause but rather moves the blocking around smartly to mitigate the damage.
A fundamentally different approach to eliminating this problem is to use a true non-blocking IO paradigm (aka NIO. aka event-based asynchronous programming, aka reactive programming), like node.js or Vert.x, where threads are never blocked on IO and we have no need of creating and maintaining worker thread pools. We will look at this paradigm in a follow-up blog post.
The term “work stealing” highlights that the worker pool “steals” some work from the calling thread.
The term “bulkheading” comes from a shipbuilding analogy where the bottom of the ship is diving into watertight bulkheads which prevents water from spreading all across the ship in case of a hull breach — the programming equivalent of a worker pool isolating all other threads from having to do a certain type of task.
Read Next : Event Based Asynchronous Programming