One of the biggest overheads of adopting a micro-service architecture is the cost of inter-service communication. The overhead comes in many forms : the latency overhead in network calls, failure of deep call stacks and error handling in distributed states etc. But to my mind, one of the most insidious costs is paid by each service in the resources that are wasted in waiting for completion of network IO.

You know how the story goes — Service A makes a call to Service B, and the thread on which the call was made waits around till the response from Service B is received, after which the sequential execution of code begins again. Also known as the one-thread-per-request model, this is the prevalent programming model in most programming languages and frameworks (barring very few).
What’s wrong with a blocked thread?
In computational terms, a thread is a very expensive resource. Some people find this statement strange, since the textbook definition of a thread is a “lightweight process”. How can a thread be expensive? The answer to this lies in hardware and programming models. A thread is a unit of computation, and only one thread can run on a CPU core at a given point of time. This means that though we can extract a lot of juice from our CPU cores and OS using smart scheduling algorithms, having a lot of threads running in an application will eventually mean that most of threads are just stuck, waiting for their turn at being scheduled at the CPU, and eventually this leads to the application grinding to a complete halt which can only be resolved by a restart.
IO blocks are the worst
If your application does a lot of calculations and therefore needs a lot of CPU, there is no way to scale it without adding lots of cores. What we are fretting over here are threads blocked on IO (data transfer over the network/database IO/file IO etc). Threads involved in these do not need the CPU, and yet interfere with scheduling by getting blocked.As it turns out, this is not really an unsolved problem today, and two mainstream computational models are available to address this.
User Space/Lightweight Threads
This model separates user space threads (threads started and used by our application) from kernel threads (those managed by the OS and running tasks on the CPUs). This model maps multiple user space threads onto a single kernel space thread to achieve a sort of multiplexing over finite number of CPUs. Quasar framework in Java and co-routines of Golang and Kotlin make use of this paradigm to achieve high concurrency. User space threads can be swapped in and out effectively because doing so does not involve the full context switch as is required for a Kernel thread. As a result, when a user space thread of Service A is blocked on calling Service B, the scheduler swaps it out for another user space thread very cheaply without disturbing the underlying kernel thread — thereby reducing the amount of switches going on in the system.

The whole architecture looks like a funnel, with a large number of user space threads multiplexing over a small number of kernel space threads, which in turn multiplex over an even smaller number of CPU cores.
The advantage of using this model is that the programming language and the OS do all the heavy lifting around making execution light weight. The programmer has to pay limited attention to how this is achieved and she can continue writing her program in the usual, linear way. The learning curve is limited to learning the right programming language (e.g. Go) or using the needed framework.
The cons are two fold. If all the application code is blocking, then at some point of time the user space scheduler will start running into the same “too many threads” problem as more and more threads are created. Additionally, there are certain method calls in this model that will block a Kernel thread even when they are invoked from a user space thread. The programmer has to be careful to identify and avoid them.
Asynchronous Programming
This model, made popular of late by Javascript’s Node framework, refers to a style where program execution is not linear. Threads submit their tasks for execution (in some way) and move on to other tasks without waiting for its completion. They are then notified when the task is complete and they can resume execution of code from that point onwards.The advantages of this model are obvious, but the actual implementation details are tricky. How do we “not” block when the programming language uses a linear execution paradigm? How do we again start executing “from that point onwards”? How is the thread stack and memory to be managed?
Two flavours of asynchronous programming have arisen to handle the various difficulties to different extents.
Thread Based Asynchronous Programming

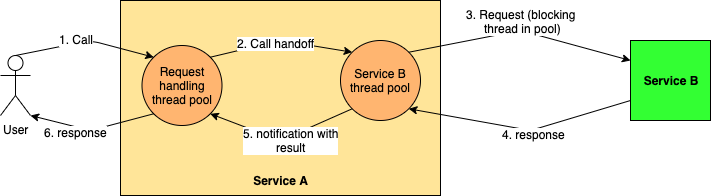
The thread based model, also known as the work stealing model, tries to achieve a semblance of asynchronicity by defining different thread pools for different tasks and having threads hand over tasks to the correct pool for actual execution and unblocking themselves. The designated pool carries out the blocking task (incurring the same blocking overhead as the traditional programming model, but over a limited set of threads) and then notifies the original thread of completion.
Event Based Asynchronous Programming
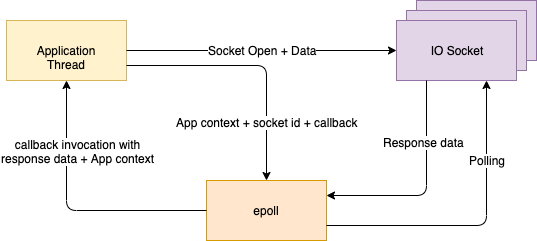
This model uses kernel capabilities to make processing truly non-blocking for all thread. A thread starts an IO task and registers it with the kernel, stashes away the entire call stack, and goes on to do other things. The kernel watches all the tasks (thereby reducing blocking behaviour to one thread in the entire system) and notifies the submitting thread with the result when the task is complete. No application thread is ever blocked — node.js servers famously employ only a single thread!
Both these models rely on callbacks to handle the “interrupt” of task completion. The control flow of the program is not linear anymore but goes goes from task initiation to the callback for task completion. The code typically looks “functional” or “streaming” in nature, with callbacks serving as nodes and work stealing handoffs/OS interrupts serving as edges of the stream.
In large scale programs, the callback programming style itself becomes a drawback, as it becomes more and more difficult to debug with control flow hopping all over the place.
Which one? Both.
Both these style of scaling applications have their own advantages, and can be applied individually or together to develop massively scalable applications. Golang uses the user space scheduling model effectively in its channel and co-routines to achieve massive levels of concurrency. Node.js is the poster child of event driven style and serves at many places as the tool of choice for building API gateways. Akka uses both light weight threads and asynchronous code to run tens of thousands of actors on a single machine.
In subsequent posts, I will explore the asynchronous programming models in greater detail.
Read Next : Asynchronous programming with Thread Pools


5 thoughts on “Overcoming IO overhead in micro-services”