Components
rulette-core
This module is the core of rulette providing all of its domain constructs and default behaviours. It defines rules and the different types of rule inputs, the different data types.
rulette-engine
While rulette-core defines the expected behaviour of the elements of the domain, rulette-engine provides the actual implementation conforming to this specification. Separating this from rulette-core allows us to modify the evaluation strategy without touching the core aspects of the system. The current engine implementation uses a Trie to manage rules.
rulette-mysql-provider
rulette-core defines an IDataProvider interfaces which rulette-engine uses to perform the CRUD operations on the actual rule store. rulette-mysql-provider module is the out-of-the-box implementation of this interface which allows users to define the rule metadata and rules in MySQL and then load them into Rulette. More on this later.
rulette-examples
This module contains some sample implementations of Rulette usage in different scenarios to serve as reference.
Low Level Design

Core
rulette-core can be roughly divided into 4 parts.
Metadata
Metadata classes make up the definition of rule system and rule input.
Rule
This is the unit of data exchange between client and rule-system. A client performs lookup/crud operations on rules via the rule-system. Rule class hides the details of rule inputs from the clients.
Rule input type
These classes model the behaviour of the VALUE and RANGE rule inputs. The evaluation of conflict and matches is implemented here.
Rule input value
These classes support the data type functionality in Rulette and encapsulate the logic of matching rule input data with incoming inputs during evaluation. Three data types are supported out-of-the-box. This means that you can defines your rule inputs in either of these types and Rulette will interpret them (in terms of range and equality operations) implicitly.
Extending rule input value
In case your rule inputs are more evolved than the primitives supported out of the box (e.g. if you want to use business objects as your inputs and define custom equality and range operations defined on them), Rulette allows you to define your own data types by implementing the IInputValueBuilder<T> interface and passing it to the rule system at the time of initialization via the RuleSystemConfigurator class.
Engine
On startup, Rulette loads all the rules from the data provider and creates an instance of TrieBasedEvaluationEngine (the default implementation of the IEvaluationEngine interface). The engine takes the rules and rule system metadata and builds an in-memory trie based on rule input priorities. Each level of the trie corresponds to one rule input, and higher levels corresponds to higher priority inputs. At each level, there are as many nodes as there are distinct values for the rule input in the rule data set.
There are 2 types of trie nodes:
Value Node : These encapsulate rule inputs of VALUE type. Locating an input value in them is a O(1) operation.
Range Node : These encapsulate rule inputs of RANGE type. Locating an input value in them is an O(n) operation (‘n’ being the total distinct ranges defined in the rules).
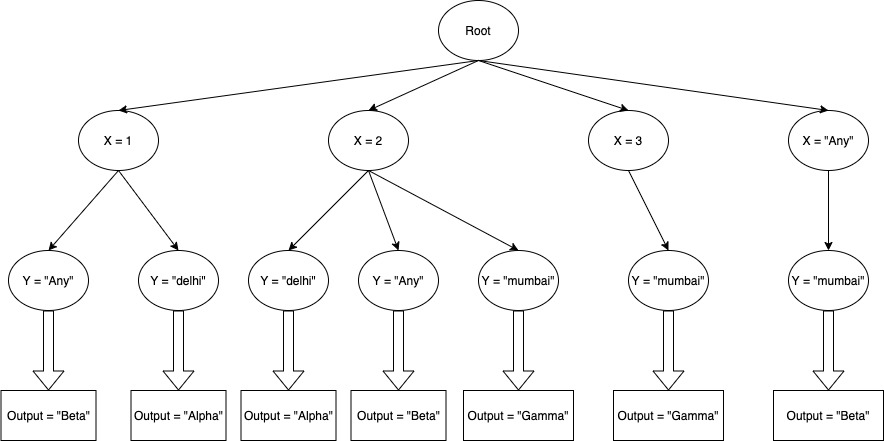
Let’s take an example of some rules. Let’s say input X has higher priority than input Y.
- If X=1 AND Y=”delhi” THEN output=”Alpha”
- If X=1 AND Y=”Any” THEN output=”Beta”
- If X=2 AND Y=”delhi” THEN output=”Alpha”
- If X=2 AND Y=”mumbai” THEN output=”Gamma”
- If X=2 AND Y=”Any” THEN output=”Beta”
- If X=3 AND Y=”mumbai” THEN output=”Gamma”
- If X=”Any” AND Y=”mumbai” THEN output=”Beta”
The trie for this rule set would. look like this.
When a rule evaluation is requested, a two-pass process occurs.
- The engine traverses the trie to find all the applicable rules (including the “Any” rules). The output of this pass comprises the behaviour of getAllApplicableRules API. If the output of this pass is non-empty, a rule is guaranteed to be returned for the given input.
- The rules are sorted based on best-fit, and the first rule after sorting is returned. This is the exact rule that applies to the give input.
MySQL Data Provider
The follow sections describe how the mysql based data provider implements the IDataProvider contract. If you are implementing your own provider (based on some other storage engine, or with some other logic), it does not matter how you implement the interface.
Data Model
Rule System
A rule system is identified by a unique name and id in a table called “rule_system”. You can define the name of the rule unique column and the output column of the rule table. Multiple rule systems can be defined in the same table.
Rule Input
Rule input definitions are stored in the “rule_input” table and mapped to their respective rule system via its id. An input must have a priority, a data type
Rule
Rules pertaining to each rule system are stored in different tables which must be defined the “rule_system” table. The names of the columns of the rule table must be “exactly” the same as the name of the defined rule inputs.