The core of building Platforms rests in versatile entity management. Entities represent the nouns or the “truths” of our world. What those entities do or how they behave can vary a lot from situation to situation, but the key thing to identify is that very often, the same entity can feature in all of these scenarios.
When we look at our systems from a business and real-world perspective, it is clear that we are working with a set of things that behave in a certain way. The business teams are focussing on getting things doing, and if two things behave in a similar way, they often think them to be the same (or at least same enough to be getting along with). There is a kind of street-wisdom in clubbing together things that behave in a similar way – even though they may not technically the same.
Early design and architecture conversations often centre around identifying “nouns” (entities) and “verbs” (actions) in the PRD and trying to determine if we are actually dealing with the same entity or with two things that act in a similar way. This is important because it exposes the full underlying complexity of the problem and identifies actors thats might otherwise slip under the radar.
However, there is the other side of this situation too – Developers like to divide things too much. It is ingrained in our training. Combining data and behaviour is one of the core tenets of object-oriented programming. If we look at something in a different context and the behaviour is wildly different, we reason the thing itself must be fundamentally different. The differing behaviours blind us from the underlying unity of the entity – developers often believe they are building a “cleaner” system when they build completely separate code paths to handle different behavioural paths.
I have written about such a scenario that my team ran into while designing logistics systems. We saw something that behaved in very different ways in different scenarios across multiple services, and we thought these were all fundamentally different things.
Both approaches suffer from extremes – one will put any two things together as long as they work the same. This is good for defining interfaces, but not for entity modelling. The other will create multiple things from one thing because it looks to be doing different things.
A platform approach bridges this gap by identifying and implementing centralized “nouns” to be what they are, and then coming up with ways to make them behave in different ways for different scenarios.
One of the concerns in creating such standardized entities is how to store use-case specific information about them. e.g. a place can be a restaurant or an office or a tourist place or all of these at the same time. We can model a place as a “Place Entity” but how can we store this additional metadata about it? Alternatively consider an e-commerce order which needs to store different types of metadata depending on which country it was placed in (Credit card info in some countries, customer’s IP address in some countries etc).
In other words, how can we design entities with extendable data models?
A Bad Idea
The most straightforward way to implement this would be if we could keep adding data fields to the platform entities data model as we came across different needs. It is is also a horrible, horrible idea.
- Not really a platform : The biggest problem is that this approach relies on making changes to the platform to address each use-case. Remember that having a platformized system means that users should be able to build things without needing the platform to make changes. This pattern definitely break this platform paradigm.
- One man’s data is another man’s cruft : Even if we were to add data fields to the entity schema to address a specific use-case, to all other tenants using this entity (who did not ask for this field to be added) this field would appear as a meaningless construct which still appears in their data domain and has to be dealt with in some way. (whether or not it can be built generically and imbibed as a first class attribute later is not the point here). This is, in a way, a violation of the Interface Segregation Principle in the data model realm.
- Schema migration : If some users of the platform schema (or some components in the larger platform itself) are applying strict checks to the schemas they are working with, they will all have to upgrade to the new schema to prevent outages.
- Tracking the origin : How does the platform team keep track that this field was added for ad-hoc reasons and its specific meaning? Additionally, we can be assured that if an empty field is seen in the schema, one or more tenants will surely start abusing it to store completely unrelated things over time. Cleanup and refactoring of platform code becomes nearly impossible over time.
- More data transfer : We are now moving more data in the form of an empty field. This may be mitigated by not moving null objects etc, but in general this is a problem.
By now it should be clear that we need a cleaner strategy than this.
Extensions local to the use-case
A more reasonable approach to extending data models can be to not allow it in the platform at all and having each use case store its own additional data locally, referenced against the platform entity that it extends. e.g. A digital order management system can extend the basic order entity schema by storing all details specific to the digital business in its own database alongside a reference to the core order entity. When any user of the digital order service reads an order. data will be read both from the core order service as well as from the its local database, merged together, and served to the user.
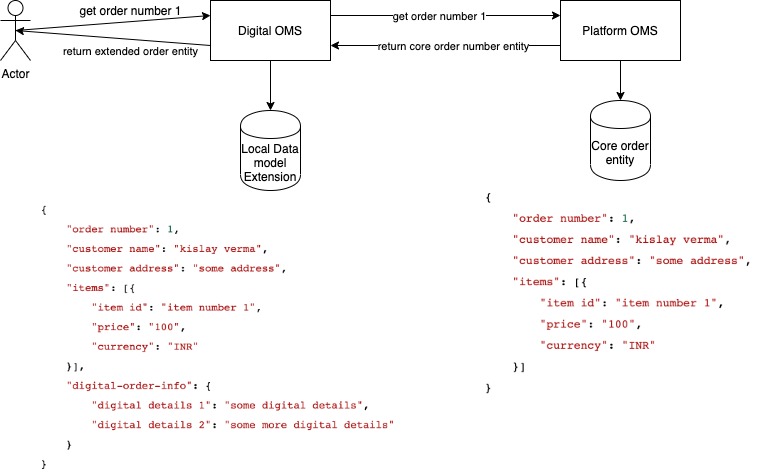
The Digital OMS now has an option in terms of data modelling – It can wrap the base order inside the digital order schema or vice versa. The former will create a new entity which can be used anywhere in the digital order service’s domain but nowhere in the platform since none of the platform services understand a digital order. This can sometimes create problems if we want to pass data around via platform services.
The latter approach enriches the existing order entity with additional data (exactly like Java’s ‘extends’ keyword does) and all of digital order service’s users can continue working with a platform entity (though augmented). We can use this entity to call platform services, but the platform implementation has to take care to not be too strict about schema validations etc.
The good part about this approach is that it is extremely intuitive (a lot of our cross-entity data modelling is done like this), has no dependency on the platform (the use-case owns the service and the local extension locally).
The disadvantages are that if you were using capabilities like data change audit trails, privacy protection etc given out of the box by the platform, we now ave to implement them on our data too (as required). There will also be performance overhead in always reading from a remote order service for every read and implementation complexity in handling the failure cases and availability.
Extensions inside the platform
Now let us look at ways of extending the platform entity directly without having to change the entity repeatedly (to take the platform owner out of the development cycle) or by encumbering all platforms tenant with the specifics of one tenant. The bad idea that we discussed earlier can be actually be modified into a viable data model extension strategy.
A direct way of doing this would be to add the capability for anyone to store key-value pairs in the entity. The platform will treat this “meta-data” like some random JSON (or binary etc) and never try to read or understand it. How to do that is left to the tenant who wrote that data. This remove the overhead of adding and maintaining multiple tenant specific field in the core entity’s schema.
{
"order number": 1,
"customer name": "kislay verma",
"customer address": "some address",
"items": [{
"item id": "item number 1",
"price": "100",
"currency": "INR"
}],
"meta-data" : {
"digital-order-info": {
"digital details 1": "some digital details",
"digital details 2": "some more digital details"
}
}
}This allows us to store arbitrary data points inside the core platform itself with a formal understanding that no platform components will ever read the extended data model. This is critical for preventing the platform from getting coupled to upstream tenant systems.
Implementation Problems
From an implementation perspective, however, there are still problems. The same entity in a tenant’s ecosystem can be extended by multiple sub-systems. e.g. An order entity may be extended by both the warehousing system as well as the logistics system, and they both might want to track “dispatch date”. How do we do this? Additionally, the interface segregation principle also applies here to keep the different tenant sub-systems decoupled – they should not see extensions that they did not make.
We can achieve this by making our metadata field a nested key-value structure (map of map) with each tenant subsystem owning one key in the top level map. The platform does not understand the contents of the map but individual systems can read their own key and then work with only their own data and extended schemas. We can go one step further by making each key a named resource in our access management system and giving each tenant subsystem access to only its resource.
{
"order number": 1,
"customer name": "kislay verma",
"customer address": "some address",
"items": [{
"item id": "item number 1",
"price": "100",
"currency": "INR"
}],
"meta-data" : {
"warehouse" : {..some warehouse specific data...},
"logistics" : {..some logistics specific data...}
}
}
}This keeps the tenant subsystem domains well decoupled, but what if the tenant’s warehousing subsystem needs to share some extended data with the tenant’s logistics subsystem? This is easily done by sharing the understanding of warehousing extended data model with the logistics subsystem and letting the latter read the former’s key. This is a decision taken completely in the tenant’s domain and the platform neither controls nor prohibits this.
It is worth noting how little control the platform is exerting in maintaining the sanctity of data. Platforms trust their users to manage their business logic and enforce only the rules that tenant’s ask them to enforce. This level of leeway would be blasphemous in a product with well defined structure. We would likely not even be talking about extendable data models.
The advantage of this is an extremely simplified development experience for the tenants – no local database has to be maintained, and all entity data continues to live in a single place. All the platform capabilities that may have been lost in extending the data model locally are available in this model.
There are performance consideration of the platforms side though. Some limit must be set on how much data can be stored in the extended data model, perhaps even at tenant sub-system level. Extra data transfer is now inevitable.
Successfully executing this model also requires discipline by platform developers to ensure that the extended data model is NEVER, EVER read.
If you like reading about platform thinking and details of building technical platforms, sign up for my mailing list and stay tuned. I publish technical articles once or twice a week.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership