Performance has always been a key feature of technical systems. Today on the internet, sub-second latencies are the norm. It costs companies money if their pages load slowly because potential customers won’t wait longer than that. On the other hand, there is more and more data from many different sources which have to be loaded into a rich user experience (think of the number of things going on a typical FB page). This data gathering problem is further exacerbated by the trend towards microservices.
Given all this, how are we to build super-fast systems?
What is caching?
Caching is the general term used for storing some frequently read data temporarily in a place from where it can be read much faster than reading it from the source (database, file system, service whatever). This reduction in data reading time reduces the system’s latency. This also increases the system’s overall throughput because requests are being served faster and hence more requests can be served per unit time.
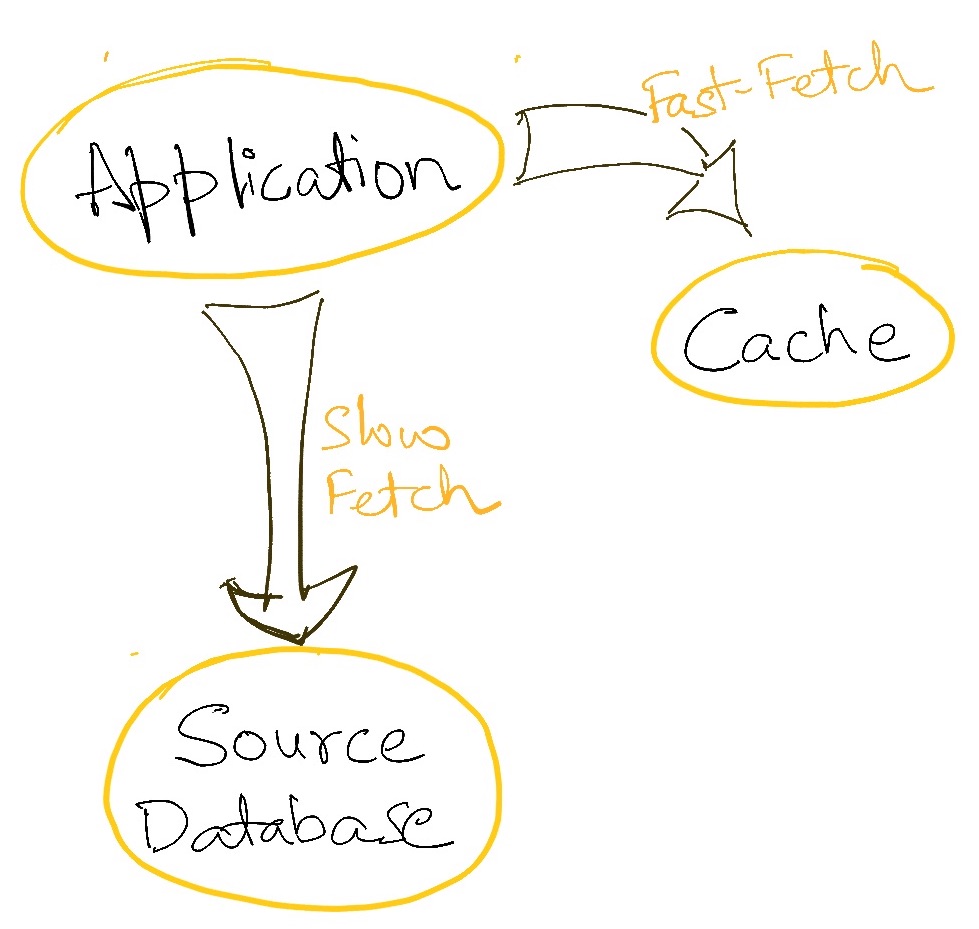
Microprocessor architectures have long employed this technique to make programs run faster. Instead of reading all data from the file system all the time, microprocessors employ multiple levels of cache where it is slower to read from lower levels than from the higher levels. The game is now one of making sure that the data read most often is in the highest level cache, and so on. Getting this right can make a dramatic difference to the speed of a running program.
Typically, caches hold a copy of the source data for some time (called expiration time or time-to-live (TTL)) after which the data is “evicted” from the cache. As more data is loaded into a cache of finite capacity, some strategies may be applied to decide which data is retained and which is evicted.
Where can we employ caching
- The system must be read-heavy – As should be clear by now that caching is only a solution for scaling the reading of data. So if you are building a system that reads data significantly more times than it writes data, caching can be a powerful technique for you. Write or compute-heavy systems have relatively less to gain from caching.
- Tolerance to stale data – Caching can only be applied if we can tolerate reading stale data (at least for some time). Since the cache is a copy of the source data, it is possible that the source data changes and the cache doesn’t know of it. Some systems can tolerate this e.g. the likes counter on your Instagram reel can be a little behind the actual count for some time. Other systems like accounting systems cannot tolerate working with stale data. If working with stale data is not acceptable in our system, then caching is not a viable option for scaling.
- Data doesn’t change frequently – A corollary to the above is that caching works best for data that doesn’t change frequently. This will invalidate the cache and push the system’s tolerance for data staleness. There are strategies to cache frequently changing data (like write-through caching discussed below), but they are usually more expensive to execute.
- Limited to the amount of data that cache can hold – In most large scale use cases it is not possible to store all of the data that you are using into the cache. e.g. You may not be able to load the profile data of all your customers into your cache because then the user data cache would be as large as the user database and that can get expensive. In these situations, we need to be smart about what is cached (the most frequently used data points) and what is retrieved from the source.
Levels of Caching
As I said earlier, caching is a general concept, not restricted to use only in web architectures. We can also employ it at various levels of the system architecture. Some of these are done by application developers explicitly, others are done behind the screens by tools and frameworks being used. I have called out some of the most commonly seen levels of caching in internet architectures, but there may be several more in between.
- Microprocessor – We have already covered this above. Microprocessors and Operating systems work together to cache data into registers and other caches to make our programs run faster behind the screens.
- Databases – Most databases employ some sort of internal caching mechanism to keep “hot” data in memory. e.g. MySQL loads small but frequently accessed tables entirely in memory. This is also typically hidden from developers, but understanding these mechanisms can be helpful in debugging database performance issues under high load.
- Application – Applications typically cache the data they own in cache tools of their choice. This is a developer-driven activity and one where we can exert the most control.
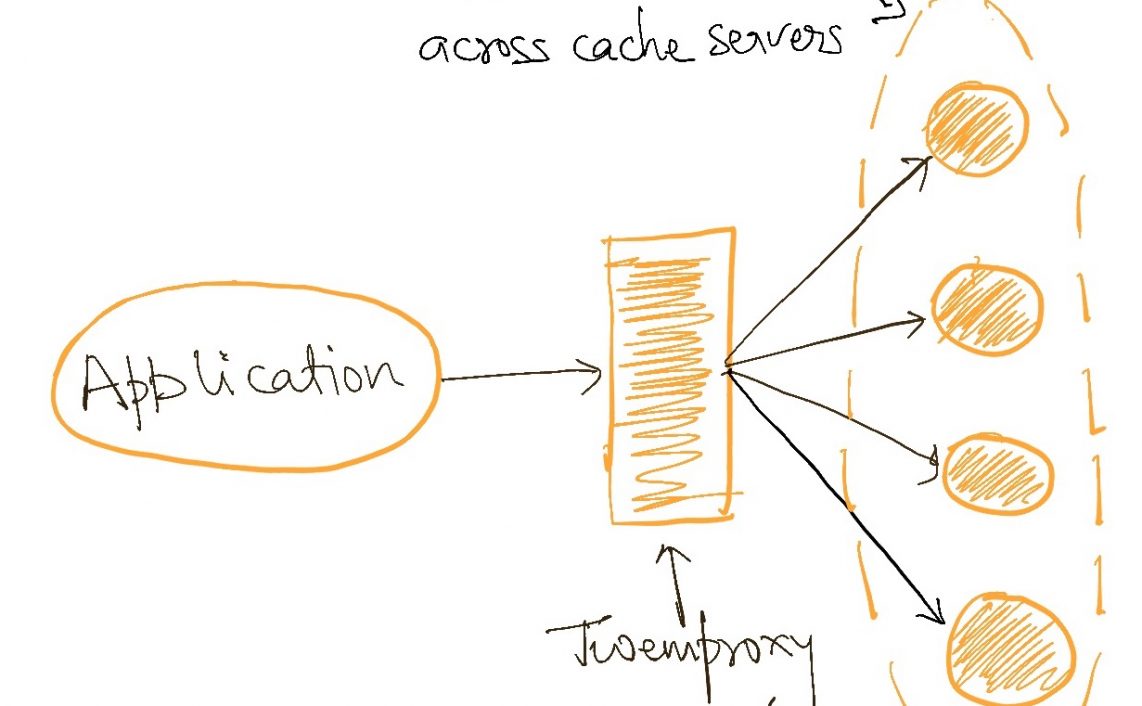
- Scatter-gather – This is a flavour of application-level caching but for applications that gather data from multiple sources (each of whom may have their internal caches). This level of caching is widely used on the internet, typically in backend-for-frontend type applications and has a significant effect on the end-user experience.
- CDN – This is “internet level caching” where we cache entire pages and distribute them across geographies so that they be read from servers very close to the end-user.
Caching Strategies
Depending on the type of application, the type of data, and the expectation of failure, there are several caching strategies that can be applied for caching.
Read through
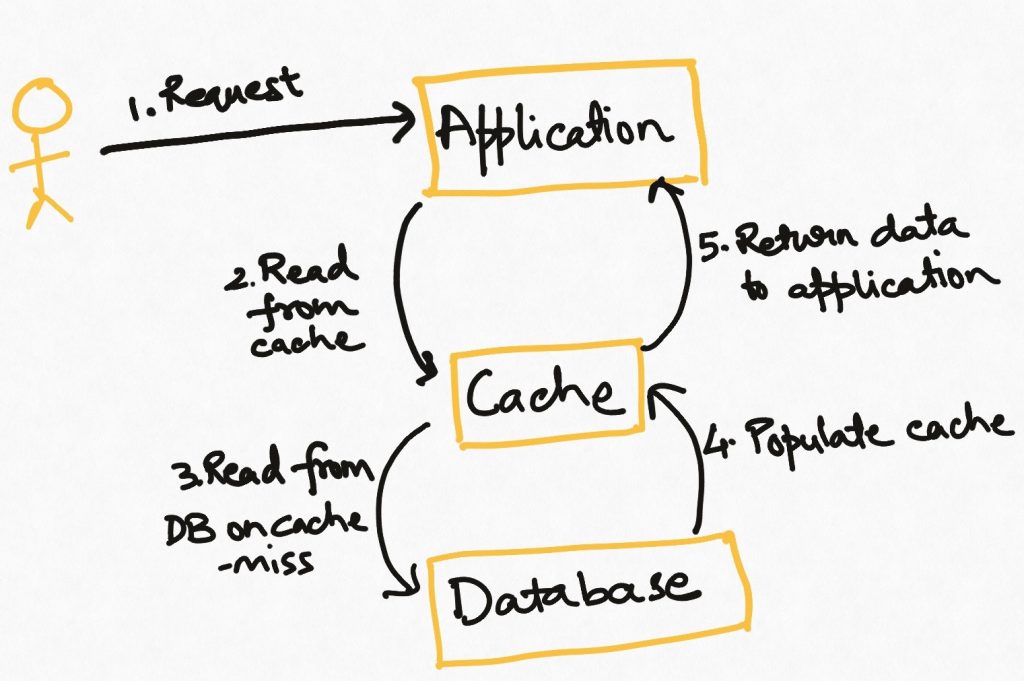
This is the simplest and most commonly used strategy. The application tries to read the data from the cache. If it finds the data (known as “cache hit”), all is well. If it doesn’t find the data in the cache (known as a “cache miss”), it goes to the source to fetch it and loads it in the cache. If the cache is full, then some policy based on the nature of the data (e.g. Least frequently used, most recently used) is used to identify the data which should be removed from the cache to make room for the incoming data.
In this strategy, tasks that encounter a cache miss will have a higher latency than those that get a cache hit.
Write through
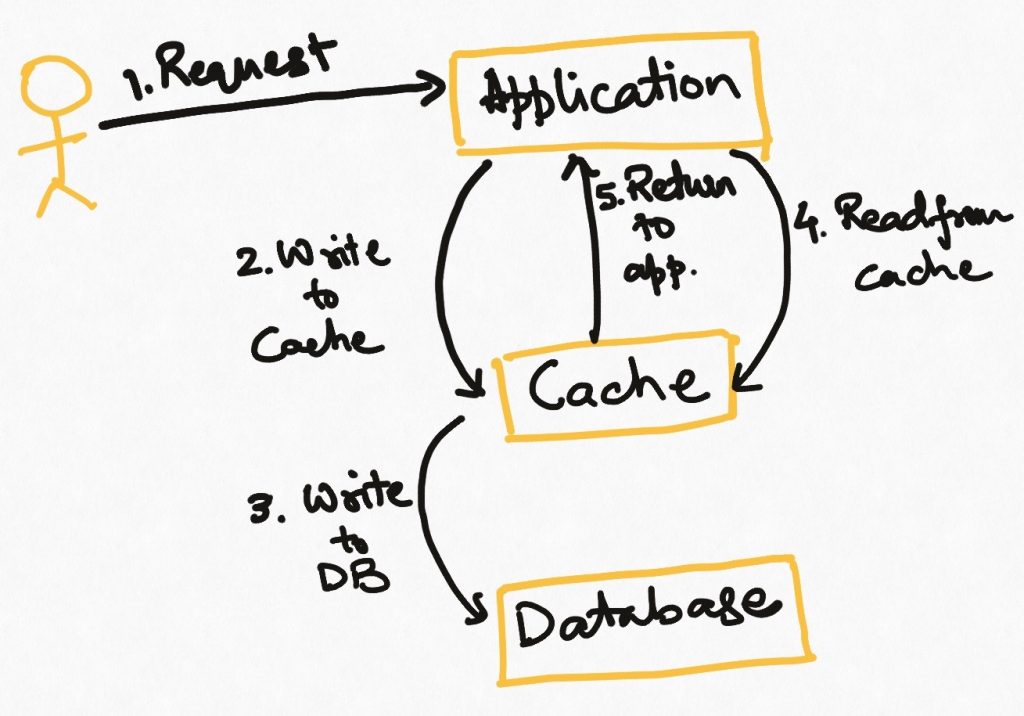
In applications where the cache can hold all the data and is expected to be always fresh, we can use the write-through pattern. In this, every write is first done to the cache, and then to the source. This means that the cache is always in sync with the source. The cache becomes the source of truth for the application and it never reads the data from the source.
On the flip side, this requires the full data to be loaded in the cache at the outset. It also introduces higher latencies on the write operations, and higher write load on the cache system, which may, in turn, impact its read performance.
Write Behind
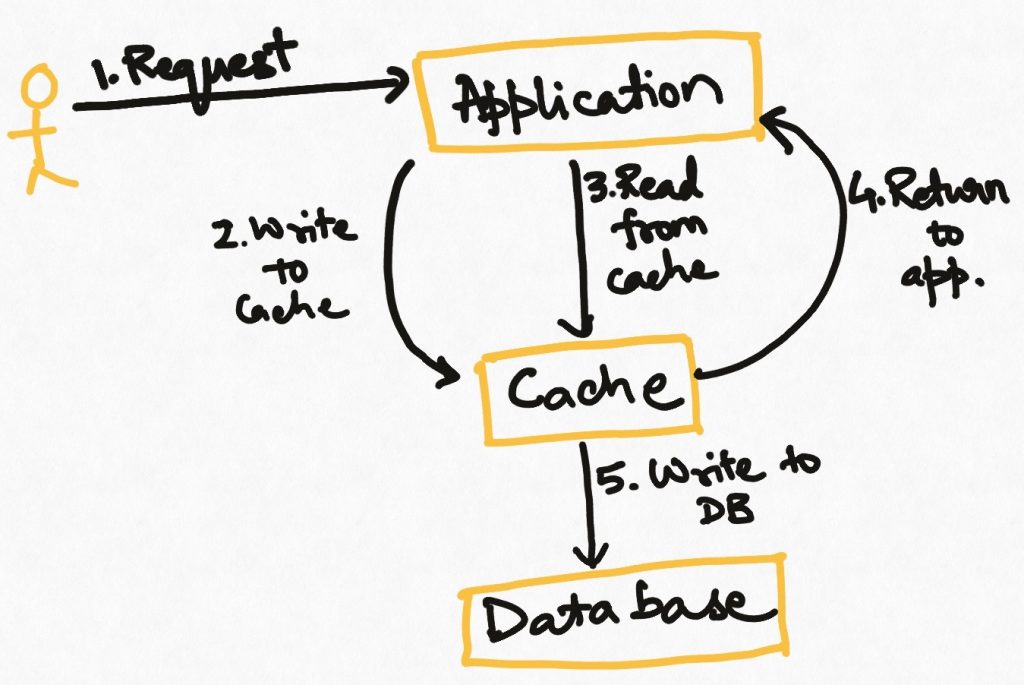
Similar to the write-through strategy, the application first new data to the cache. But after that, the application process returns to its main duties. The cache itself or some other process runs periodically and batch-writes the cache data into the source.
This is an effective strategy for cases where we do not want to bear the latency cost of writing to the source in the main application process and the cache is reliable enough that we are sure of not losing the data before it is pushed to the source. This strategy requires that writes to the source never fail while dumping data from the cache, or there be a resolution mechanism to resolve inconsistencies.
Refresh Ahead
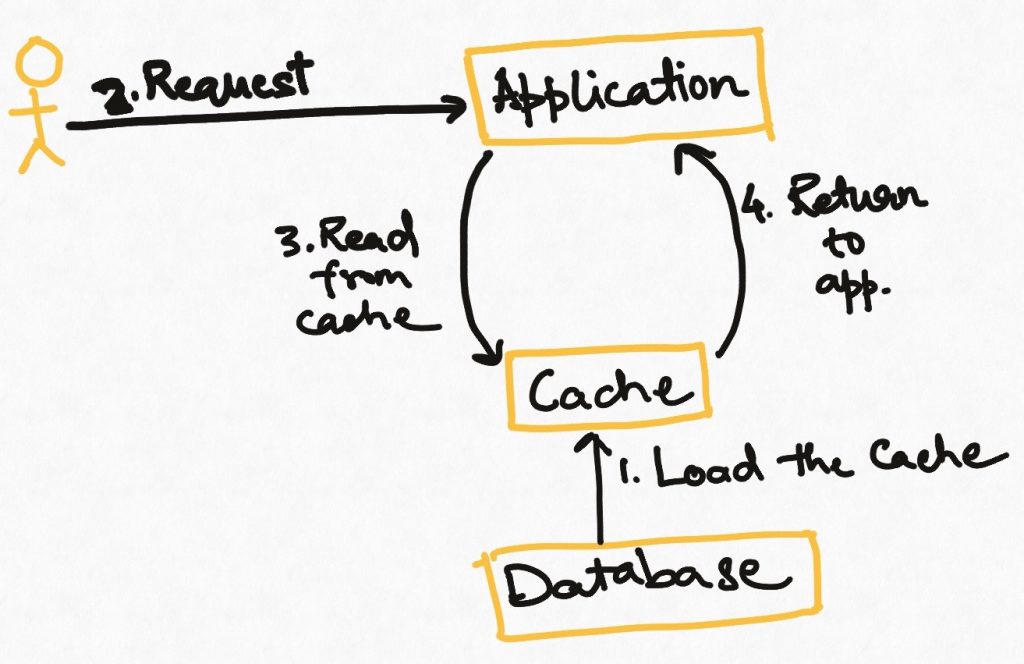
In this strategy, we pre-emptively refresh all or part of the data of a cache as it is reaching its expiry time. How to decide what to reload is up to the application. Note that the application may still face cache misses if not all data can be reloaded, and there this technique is usually combined with “read-through caching but with the idea that reloading process should make cache misses rarer.
This is not a very common technique because it requires setting up a process to identify expiring data and reloading it based on some smart logic. This is usually not needed by applications.
Choosing a cache implementation
Now that we know of the various caching strategies, let’s consider what kind of cache implementation to actually use. While technically any data structure/medium that is faster to access than its source version can be used for caching, typical cache implementations are key-value stores of some sort. Three types of cache implementations are popular.
In-memory
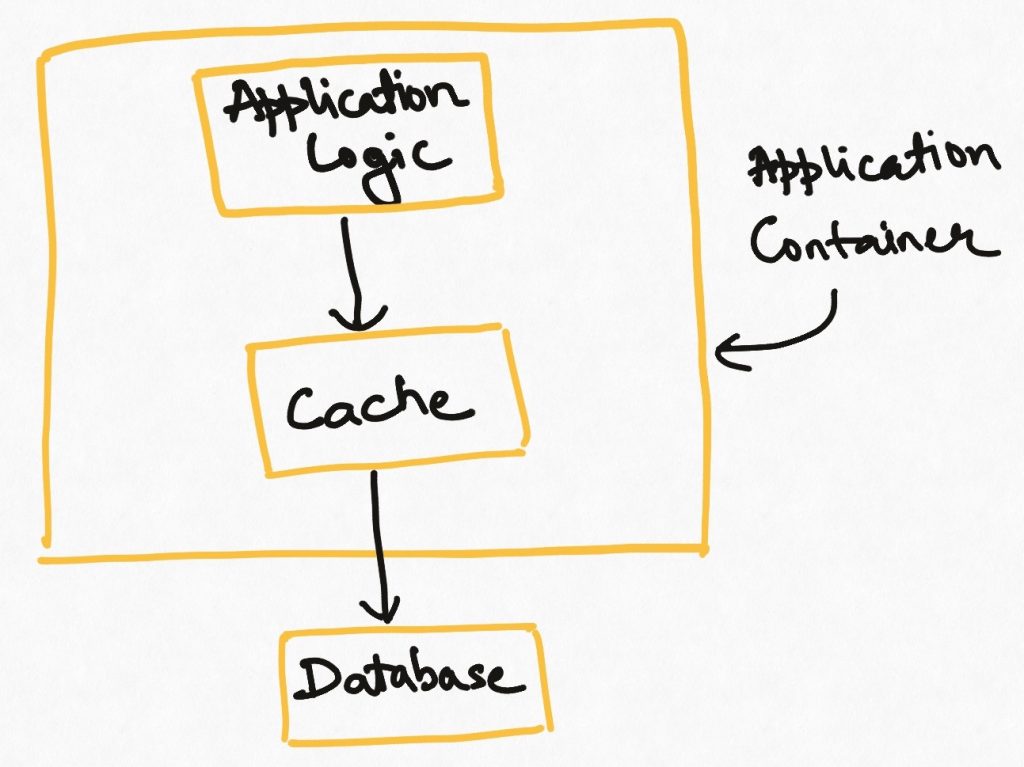
This is the case where the reading application loads the data into its main memory (as a hash table or map) and uses it as the cache. This makes for the fastest possible access since the data is available literally like a program variable. It is also the simplest possible implementation since it does not introduce any new elements into the system architecture. Many libraries are available to abstract the implementation details of caching/eviction etc from user code.
There are also several downsides to this style. The cache lives inside the application, so if the application goes down, the cache vanishes and has to be rebuilt while launching the application. The memory footprint of the application increases and the amount of data that can be cached is limited by that. This type of cache is also local to the application server. If you have multiple instances of the applications running, each of them will have its own cache (waste of memory) and these may be temporarily out of sync with each other if one instance reloads its cache while the others still haven’t.
External
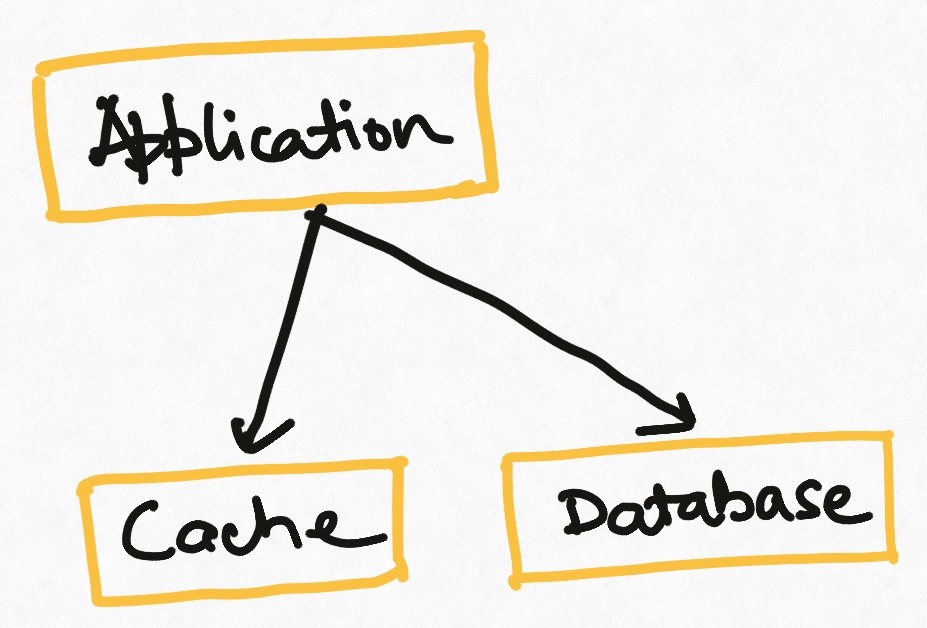
We can use a standalone system like Redis or Memcached as an external cache. It is essentially like having an external server that all nodes of an application talk to and which stores the hash table instead of storing it inside the application. This introduces a new element to manage in the architecture but creates a central cache that is durable and ensures that all instances of an application see the same cache value.
This type of cache has the problem of failure tolerance. If the cache server crashes for any reason, the application will fail. This is solved by some implementations by having redundant caches which are kept in sync with a “leader server” but that can step in if the leader fails (Redis Sentinel uses this mechanism). This gives failure tolerance at the cost of design complications.
External Distributed
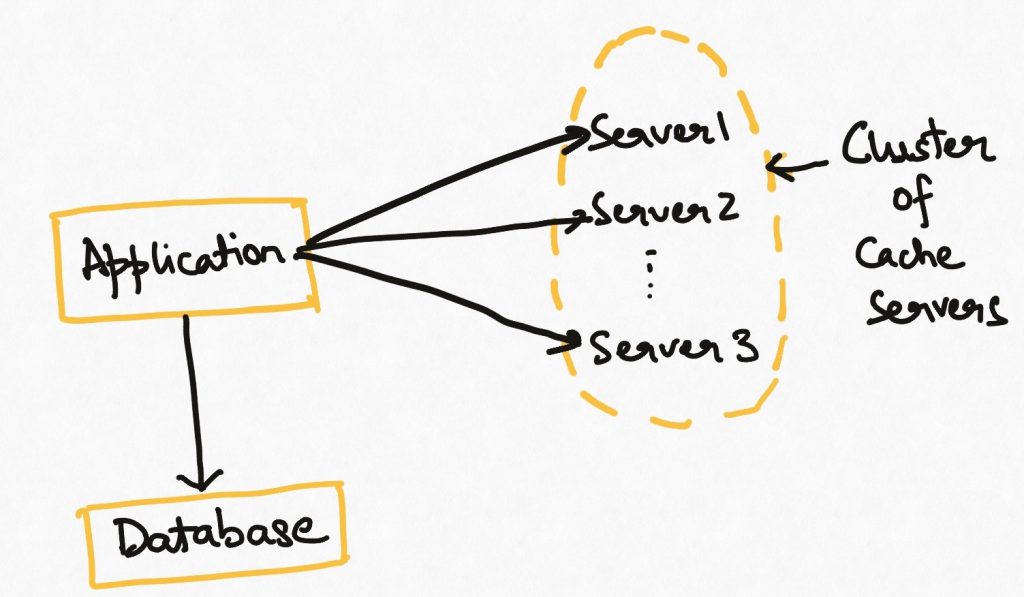
Both the in-memory cache and the external cache suffer from some scale problems. The amount of data that can be stored in either of them is limited to the memory size of a single server. As large scale systems emerge and the volume of data to be cached increases, this becomes a bottleneck.
To overcome this, we can use an external yet distributed cache implementation e.g. Redis cluster. In this architecture, the data is distributed across multiple instances of the cache servers. More servers can be added to this “cluster” as data size grows, making this architecture horizontally scalable. Data distribution among the servers is typically managed by the cache implementation itself. The reading application can continue to treat the cluster as a single entity when reading data.
This is a full scale distributed architecture and comes with all the associated problems like node failure, split-brain, data redistribution etc. It is also the only feasible architecture at the highest web scale.
TL;DR
Caching is a powerful scalability technique that can be used in many different scenarios and in many different flavours to speed up the performance of our applications.
In the next part of this series, we will look some more nuance in the use of caches and a specific but deadly failure pattern in systems that rely on caching.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership

Hi Kislay,
Great introduction on caches.Couple of points wanted to discuss below:
1.I think “read-through” cache mentioned in the article is actually “Cache-aside” strategy.
In “read-through” the caching framework itself is responsible to update its cache(e.g guava etc) while reading from secondary source unlike “cache-aside” where application handles it.
2.Can “write through” combined with “read through” be a good alternative for systems which cant’ have stale data use case(e.g financial transaction systems).??
By avoiding caches, they might anyway need to rely on a datasource with disk and these systems have almost similar number of read and writes.