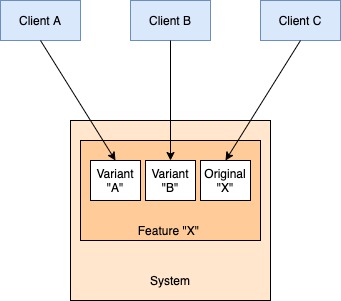
Consider this fairly common scenario. A team builds a system that is meant to be used by the entire company e.g. a video management platform (VMP). This system is supposed to take care of all needs like video storage, editing, bitrate optimizations, delivery/CDN, etc so that no one else has to deal with them. You just bring your video and all else is taken care of. As a result of this overarching goal, only one interface is exposed to the user of the system to consume its capabilities – the bring-your-own-video API/UI. This is great for the major use-cases and teams start adopting this new Video-Management-Platform quickly.
At the same time, new requirements start popping up which require only content distribution, or optimization, or only storage. However, none of these capabilities are available for use in the VMP. So to unblock themselves, teams start going around the entire system and building their own specific, small solutions that are just enough to meet their needs.
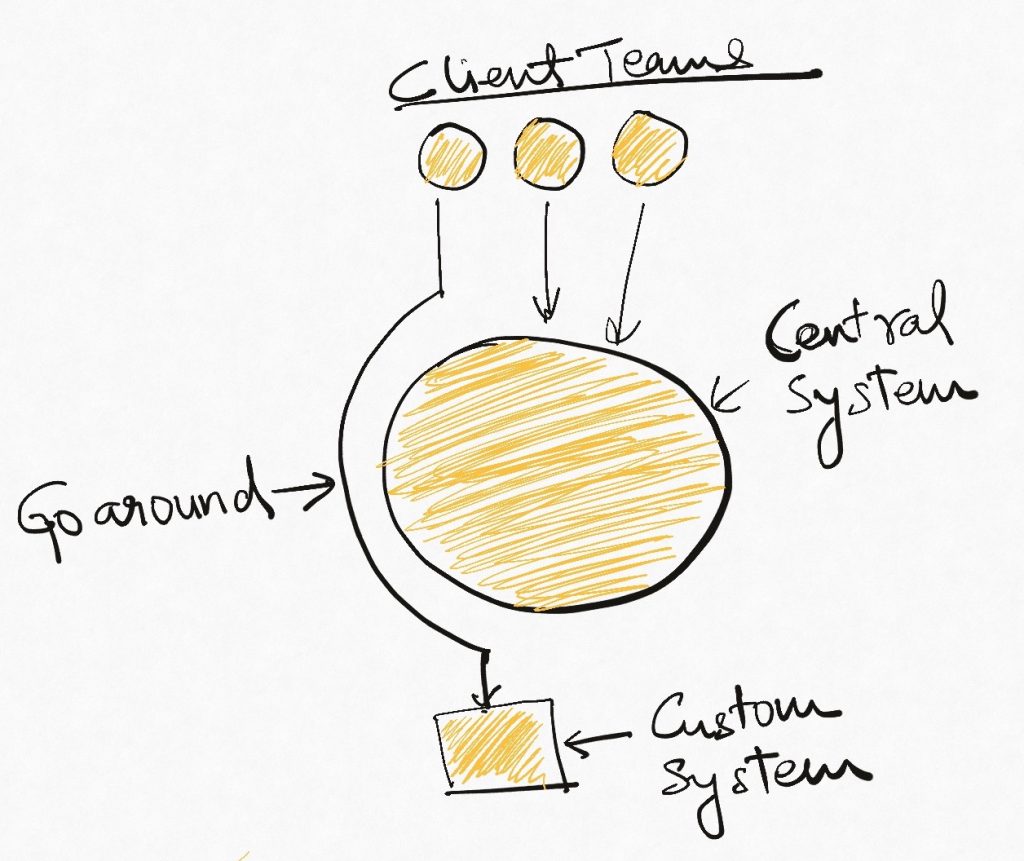
End result? We are back, kind of, to square one. The overarching VMP was intended to solve all video-related needs in one place. But in the final accounting, the organization still has scattered (and duplicated) bits of video capabilities, each tailored to the needs of the team that built them.
What went wrong
The team that built the VMP took the product experience as defined at that time (just bring-your-own-video) and embedded it into the system architecture literally. They hid all system capabilities behind the opinion that there should only be one way to use them. As a result, when opinions changed, there was no way to leverage the existing capabilities because they can only be used in the context of bring-your-own-video. This tight coupling at the system architecture level meant that other teams that had to deal with a changing landscape (typically product-specific/vertical teams) had no choice but to bypass the entire stack and build their own things.
This problem of go-around in systems that are expected to be central/platform/generic occurs often. The best designs often abstract the most, and while this is a great characteristic in small systems and end-user products, it turns out to be an expensive mistake in building large scale architectures. This is because most large software systems are composed of the ability to do multiple similar things. If abstracted behind the facade of the larger product, these capabilities become inaccessible in other scenarios. We lose agility in responding to change since we no longer have the building blocks to create new things.
This has ramifications beyond just technical coupling and duplication. Products that do something well also often do it only in a certain manner. Strongly abstracted systems simplify many things, but they can lock the organization into patterns of behaviour. If there is only one way of using the system’s functionality, the organization often organizes along the same lines in behaviour (and vice-versa). Three outcomes are possible.
- Use cases get force-fit into the product. While this is manageable if the leadership is keeping an ear to the ground, the likely outcome of this is the accumulation of tech debt in a previously solid product and all the bad things this eventually leads to.
- Technical teams go-around the central product to reinvent the wheel in specialized ways. This is a waste of engineering resources.
- Business teams modify their processes into sub-par versions because that is the only version of the process that the technology can support. This is bad for business beyond just the technology team.
Scope of the go-around decision
One argument against all of this is that product teams should simply have modified the product to unlock the capabilities or the team that owns VMP could have done it for them. This is possible but complicated because it requires something very difficult – coordination between two teams.
The first step is to determine what changes are needed in the existing system. Either team independently, or the two teams jointly need to figure out what is to be changed and what it will cost. This exercise might be time-consuming by itself in poorly documented systems.
Now that we know what changes are to be done, who should do them? Should the VMP team do them by dropping some other things it was planning to do. Or should the team which wants the change do it in an unfamiliar codebase whose operational responsibility it does not have? Both are difficult decisions.
In opposition to all this ambiguity, there is a simpler choice – just build something small and quick for the new requirement. It doesn’t have to be great as long as it serves a limited purpose. We can always talk about consolidation with VMP “later”.
Go-around limits the scope of the decisions that the team has to make and is one of the reasons it is the route taken so often.
Platform Thinking to the rescue
Applying platform thinking to the problem offers a simple (not easy) way out – separate the capabilities of the system from the specific uses of those capabilities. Also known as the Golden Rule of Platforms, this allows a team to identify core building blocks of a platform that can be used to build more than one product.
Thought of in this manner, building a VMP means first identifying all the capabilities that need to be present to build it, building these capabilities independent of the requirement for a VMP. The more we can build these capabilities as standalone constructs, the better it is for the architecture in the long term because these are the blocks that will be difficult to bypass. An existing, atomic system that offers a single functionality and is easy to integrate with is our best insurance against changing needs.
I’m not suggesting that we build feature complete versions of all these sub-systems. What we should build is a structure that identifies them as independent, self-contained constructs that have a definite boundary and purpose. Richer functionality can emerge over time within that boundary. A video encoding system should be identified and built which does only encoding and has interfaces only for that purpose. The types of supported encodings supported can grow over time, but we should first identify the scope of this system. The plan to build a VMP on top of this has no role to play at this time.
Perspective: product-first to platform-first
One trick that makes the platform perspective possible is the inversion of the design approach from product-first to platform-first. A typical system design approach would start from product requirements and then design a system that would fulfill these requirements. The resulting design might be modular, maintainable, etc, but its structure, like the mindset of its designer, is tied to the product requirements. It only evolves as the requirements of THIS product change.
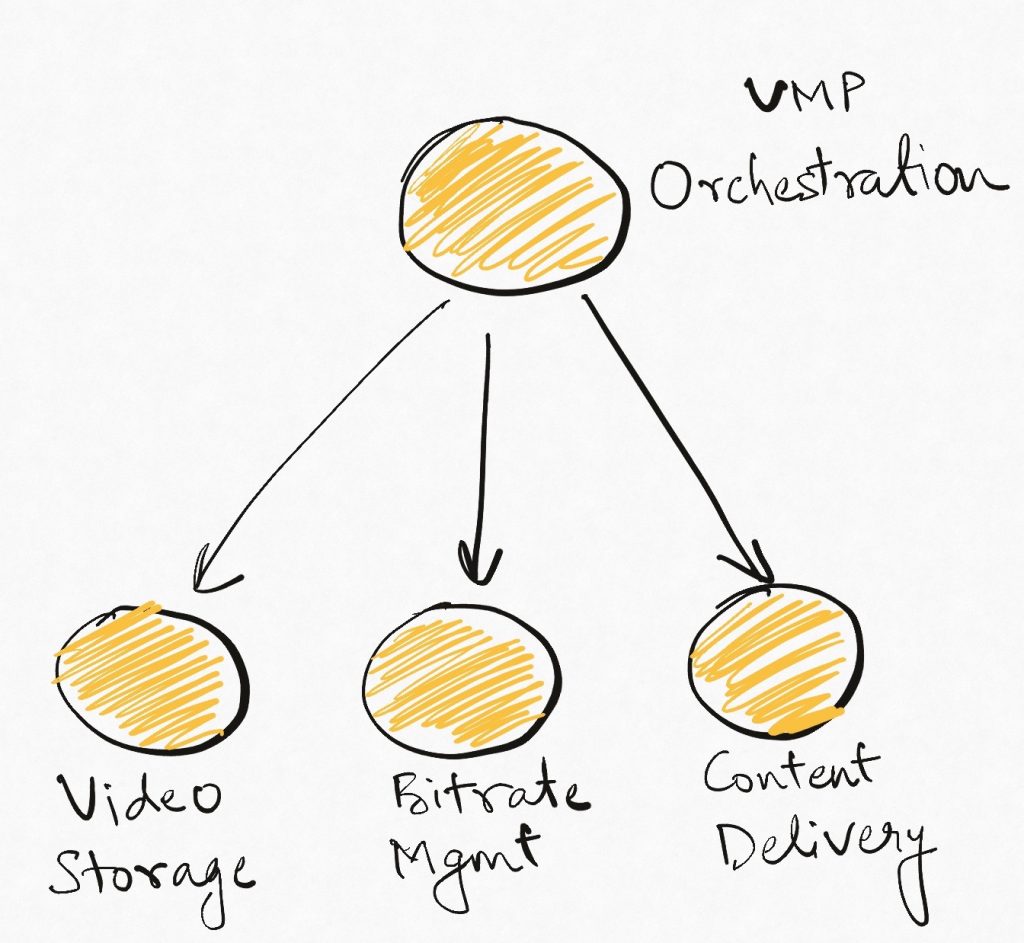
The image above is a typical component diagram that you might expect for our VMP. The problem here is that all those modules paint a misleading picture. While they represent capabilities that the system builders think of as independent, they are actually independent “only within the context of the larger product”. The product perspective embedded in the design is likely to create co-dependent sub-components rather than independent systems.
This product perspective in system design is part of the reason why coupling emerges even in microservice architectures where different microservices are expected to be independent of each other. The real problem lies not in the architecture/design pattern but rather in the design mindset.
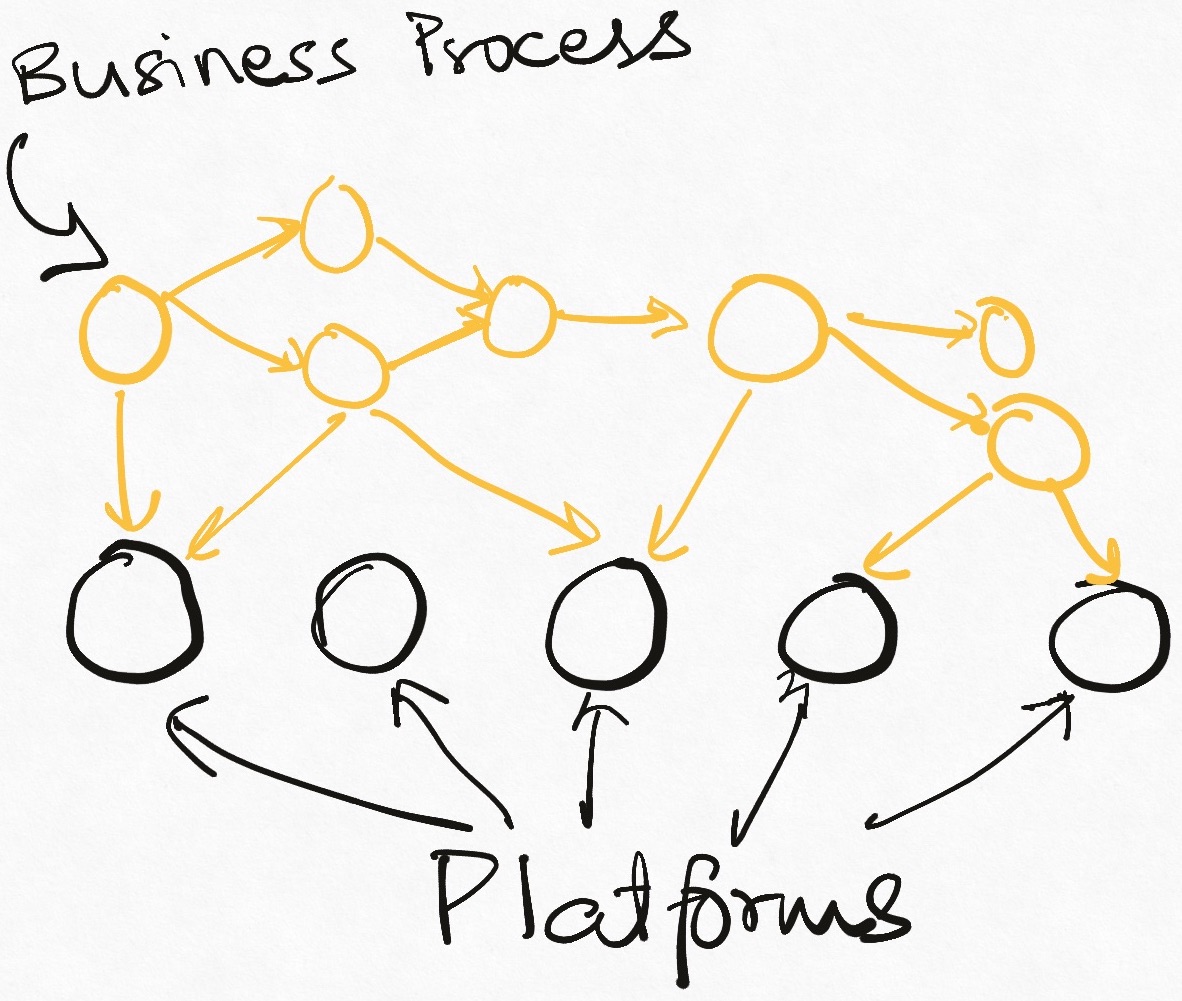
Platform-First thinking approaches this problem statement approximately bottoms up. We analyze the product requirement to identify the underlying capabilities required to build it. Once we have this list, we forget about building the bigger product and focus solely on the sub-parts and design/build them all by themselves. The resultant architecture, thus, grows outside in (all systems have their own requirements and boundaries) and bottom-up (lower complexity systems are built first and then composed into higher complexity systems).
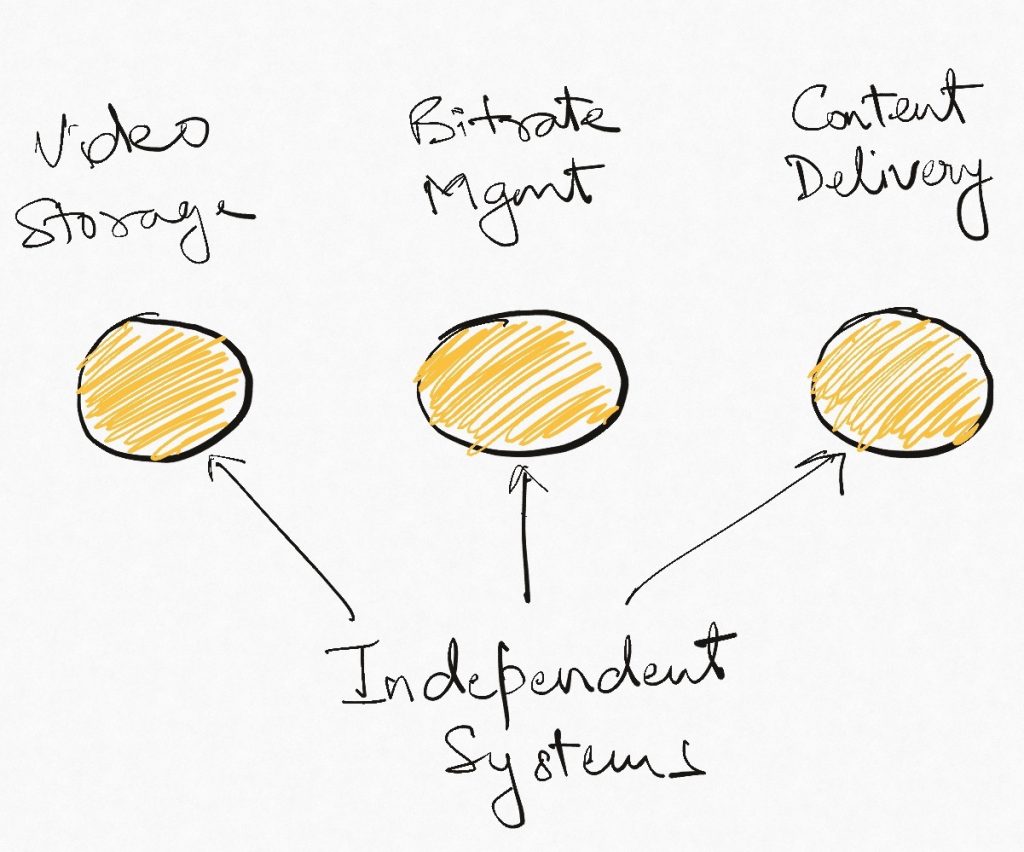
Once these systems are ready, we switch back to building the main product. The platform components continue to operate standalone and any team with divergent requirements can use them on their own, thereby removing the notion of go-around completely.
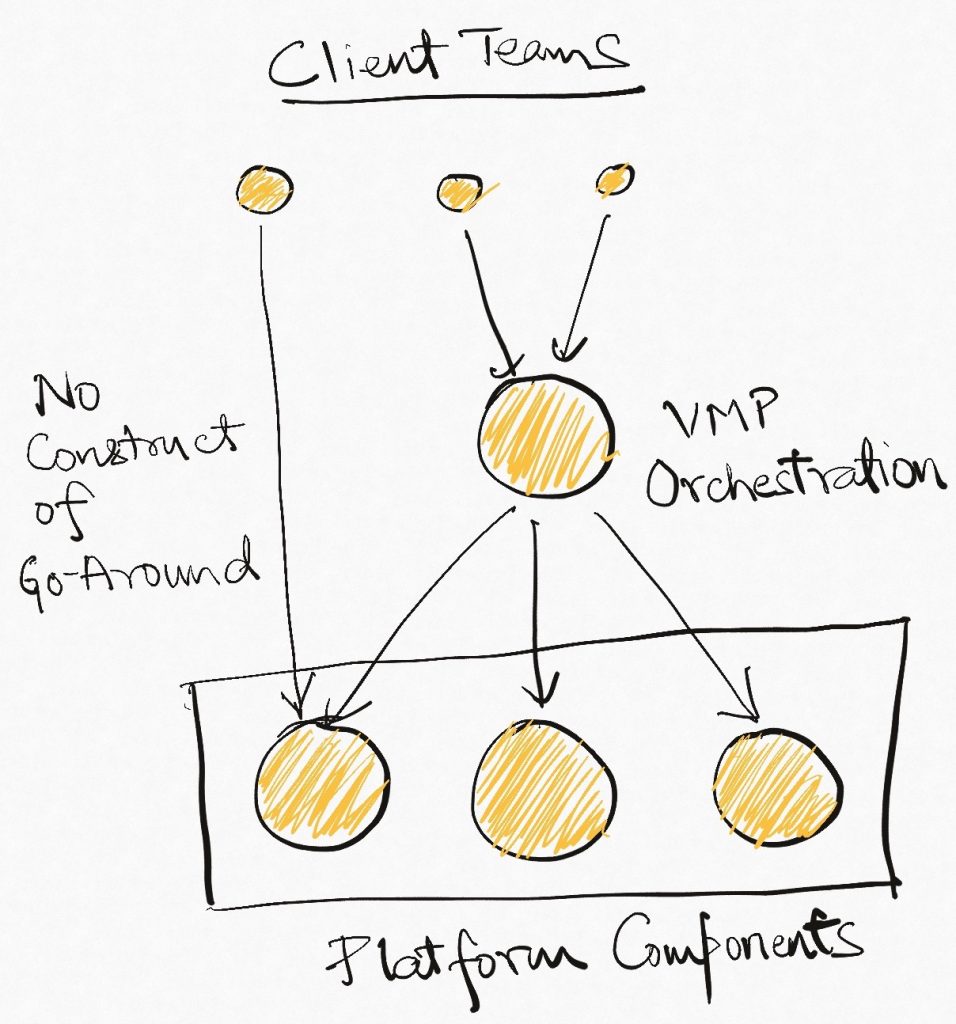
While this inversion of design perspective in no way ensures that independent components will emerge (developers are human after all, and it is difficult to not think of the main deliverable and the deadlines around it), it makes it far more likely.
Scope of the go-around decision
Pre-existing platform components are a deterrent to the dreaded go-around. For one, the capability that is required for a new use case might already exist in a perfectly reusable manner.
Even if there are enhancements required in the existing component, it is easier to approach them because the scope of the component will be lesser than the complete VMP. The cognitive load of understanding the system and the implementation overhead of making the changes are both likely to be much smaller – likely far lesser than building something ground up.
The technical and the delivery incentives both align in favour of adopting and enriching the existing systems rather than going around them.
Summing it up
Designing a system with only the final product in mind has the flaw of fencing all aspects of the design with a boundary defined by the product experience. Any variation on the requirement becomes hard to accommodate and the system becomes less nimble.
This problem can be mitigated by identifying the capabilities required for the product as standalone systems, building them independently, and then composing them into the necessary product experience. This creates versatile building blocks that can be combined in multiple ways to create new products as the need arises.
Read Next: Designing extendable data models for platform systems
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership