TL;DR – Hierarchically arranged API gateways can be used to build “macro” bounded contexts. This can make microservices “less”of a problem by reducing them to an implementation detail within that macro context. This results in a simplified architecture composed of stable interactions between hierarchical domain boundaries.
Microservice architectures have many advantages as well disadvantages, and the internet is rife with debate about the size of a “micro”-service. A less talked about problem is the “conceptual sprawl” that individual microservices modelling a rich problem space create. There can be dozens or hundreds of well-defined bounded contexts each represented by a microservice.
However, discovering the right combination of these services to fulfil a new business requirement becomes an increasing challenge. Each individual part (service) may be well designed, but we start losing our way in the exponential number of interactions between them.
Case Study : Backend for Frontend
A “backend for frontend” is a service supporting a frontend by combining data from multiple underlying services. This is the node server backing a react app, the controller layer behind thymeleaf/JSP pages and so on.
Let’s walk through how new UIs are often built. The first version almost always directly calls existing APIs across many services (likely because there aren’t many such calls). As more and more services need to be called and their data merged into each other in more complicated ways, a debate arises as to whether all this should be done in the frontend or the backend and which team should do this.
The typical response these days is to spin off a “service” which does whatever the frontend team wants it to do.

While we can think of this new service as a system that supports a particular UI, what it is actually doing is providing an abstraction that allows the frontend to have only a limited exposure to the full complexity of the backend.
The Cognitive Overhead Problem
The problem described above happens because a single frontend team cannot possibly deal with a microservice-based backend fragmented into tiny “domain” capsules exposed all at once. The cognitive overhead in combining these tiny pieces into larger things is tremendous. One has to understand all of them as they relate to each other and the ways they communicate with each other (e.g. are they eventually consistent with each other? Do they have independent state machines and how do they relate to each other?).
The other problem is that the underlying architecture is constantly shifting, with more microservices coming up, services getting deprecated and changing contracts etc. All this makes our “abstraction service” brittle. The microservice owners have to be on the lookout for all consumers lest they break them with any change. Service users are always tinkering with their service to keep it in line with the underlying services. Migrations become a permanent fixture on the sprint board.

Given this scenario, a specialized solution in the form of one service for one UI is actually a good solution – it is the only way to move forward! Anyone looking to combine information across multiple domains as defined by each microservice has to create a solution of their own because that is all they can do.
But in the larger scheme of things, this is clearly not a good place to be in. How can we reduce this complexity in combining things so that we are better able to leverage the existing systems?
Organization in Complex Systems
Here’s a quick, shallow recap of organization in complex systems.
Complex systems are made of hierarchies of independent subsystems. The hierarchical arrangement emerges as an evolutionary response to changing environment and leads to more and more sophisticated features. Each level is a response to needs faced by one or more lower level systems and it abstracts their details while still facilitating their functioning. The overall system is therefore partially resilient to failure of its somewhat independent subsystems. Collectively, this gives to an ever rising dynamic complexity which is highly resilient and adaptive.

If this sounds remarkably similar to distributed system design (buzzwords et al) because it is. Large distributed systems are rich complex systems with all constituent parts interacting with each other and triggering concurrent changes in each other. So let’s try to bring some systems thinking to bear on the problem of custom backends-for-frontends.
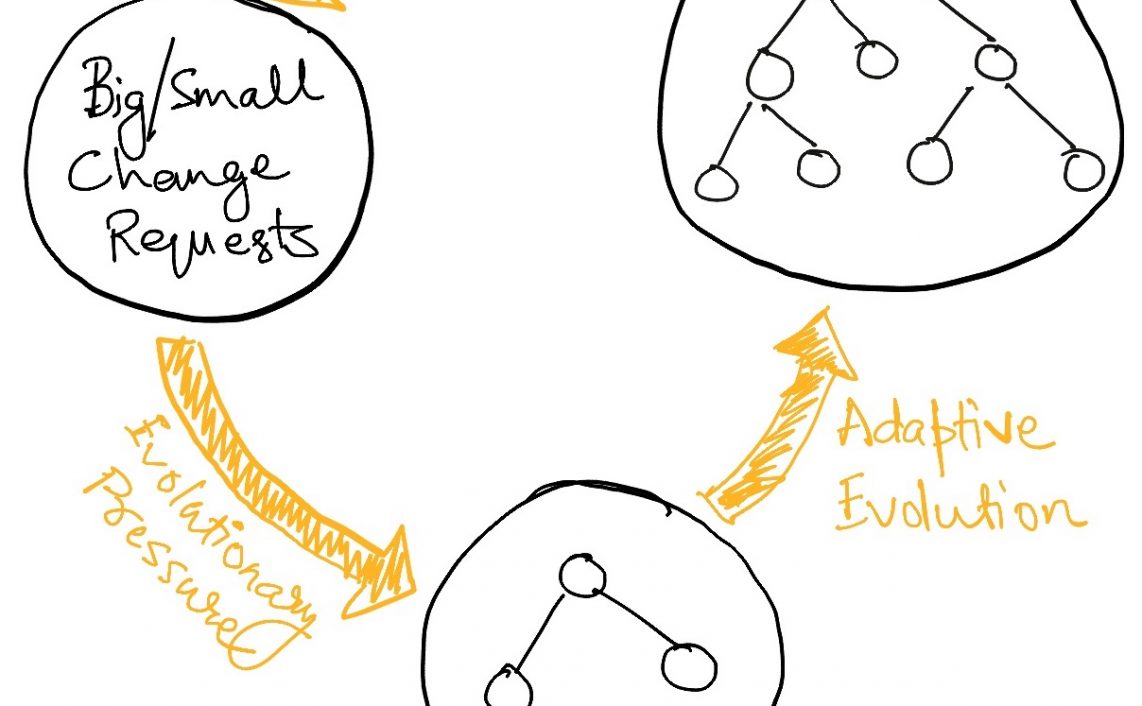
The custom backend-for-frontend we just saw is the microservice architecture’s highly specialized evolutionary response to the pressure of the external world, viz. the functional requirements of the frontend and the limited time in which to meet those requirements. Evolutionary timescales are generally long because the system tries out many combinations before “discovering” what works best in the new environment. However, by putting a timeline on “survival” we have hamstrung the usual mechanics resulting in a system response much like growing corns to protect against shoes that pinch instead of allowing better shoes to “emerge”.

The evolutionary pressure is also intense because there is no sense of hierarchy in our microservice architecture. The entire complexity of the domain is laid bare all at once to everyone. While upstream-downstream relationships can be inferred between domains looking at data and call flow, there is no concept of hierarchy of ideas that can simplify comprehension for new users.
So while domains are the building blocks of our systems, we have not yet managed to layer these building blocks in layers of increasing complexity in representation and function.
Domain Modelling is Hierarchical
Bounded contexts are the philosophical building blocks of microservice architectures. If we want to layer our architecture, we need to layer our concepts. And as you might imagine, this is not difficult at all! We have the entire organization’s structure to be inspired, and since domain driven systems tie in very closely with how organizations are organized, there is plenty of opportunity to copy-paste.
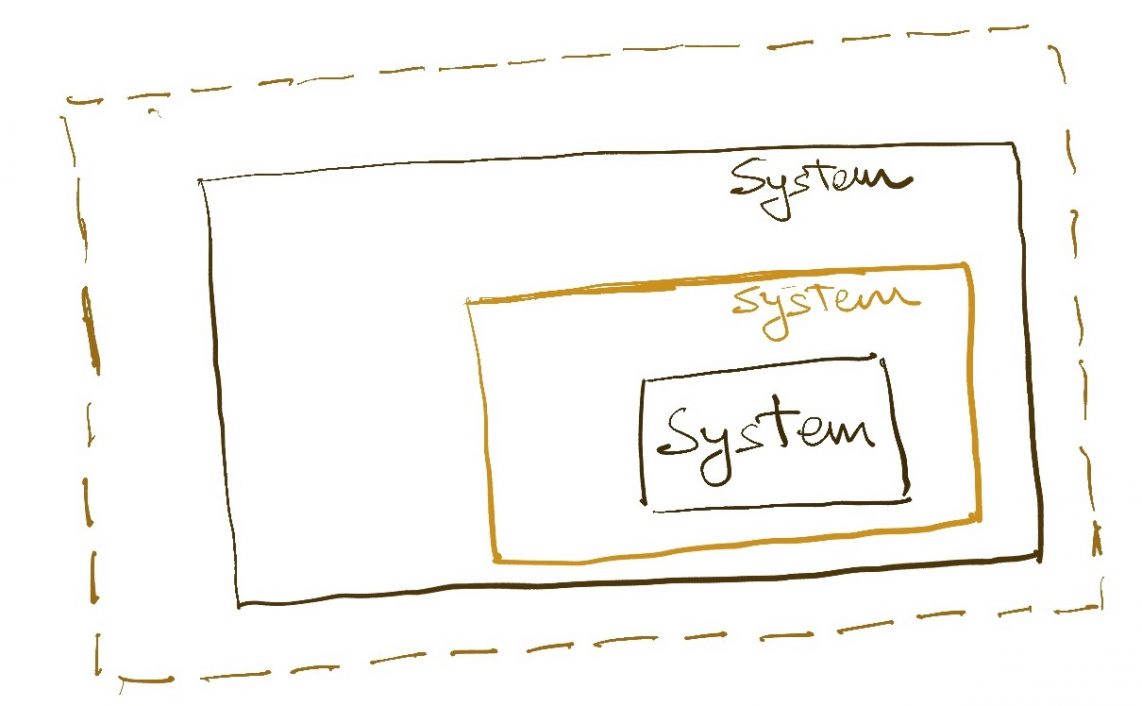
Our organization’s structure clearly tells us that a “domain” can mean very different things at different levels of abstractions. As soon as we say “abstraction”, we know that we are in a hierarchical world.
If you have ever seen a junior developer try to explain a production outage to a senior manager, you know what I am talking about. The minutiae of system implementation don’t matter to the senior manager because at his level of operation, “outage due to timeout in calling payment authentication service from checkout validator service” is interpreted as “outage in checkout due to payment system”. He doesn’t care about “timeout”, “authentication”, “validator” or “service” – he cares about “checkout”, “outage”, and “payment”. The CEO doesn’t even care about “checkout” and “payment”, he probably just hears “tech” and “outage”.
This gives us a direct line to solving our problem – let’s bundle our bounded contexts in a way that all contexts in one group can be represented by one word. This is the reverse process of how we break down the system into microservices; a microservice-to-monolith migration, if you will.
Representing domain hierarchies
So we want to bundle multiple closely allied domains (physically represented by their corresponding microservices) into a single umbrella.and then those umbrellas into a larger umbrella and so on. Note that the bundling process is subjective because people can disagree with what “closely allied” means. An instinct for naming is a good guide – the collective name should not sound dissonant from the individuals.

In the real world, a higher level domain can be represented by a separate team (Payment Coordination Team) or a separate manager at a certain level (VP, Director, Architect etc). How do we do this in the technical world? If we want to build an interface that can span across multiple internal systems and combine them into a cohesive experience wrt system vocabulary and capabilities, then we need not look farther than an API Gateway.
API Gateways
API gateways are used as single points of ingress and egress of data from the system. They are typically the points where administrative functions like authentication, rate limiting etc are applied. Companies often employ “public” API gateways to expose a limited subset of their tech stack to external users (external meaning any software not running on the company’s servers, including mobile apps).

The traditional role of API gateways has been that of gatekeepers of all traffic coming into the company. They are meant to be lightweight with no business logic (though they may contain minimal schema transformations), and they often expose an aggregate of the capabilities of multiple internal components as a single unit. E.g. Signing up for a website via its API gateway might create an account in the “User Service” and create a newsletter subscription in the “Newsletter Service” in one go.
API Gateway as domain boundaries
The backend-for-frontend we saw earlier is essentially an API gateway designed from the wrong side, i.e., by consumers of the API rather than publishers of APIs. The consumer is compelled to do so because no standard conceptual hierarchies exist for them to leverage.
We can apply this API gateway’s aggregation capability in an internal context to develop coarse-grained system boundaries between our microservices to model hierarchical domains. We can hide the microsevices we had previously put under the same umbrella behind an API gateway which now represents the new domain boundary. No one is allowed to call these services directly. Any capabilities that need to be exposed must be exposed via the API gateway.

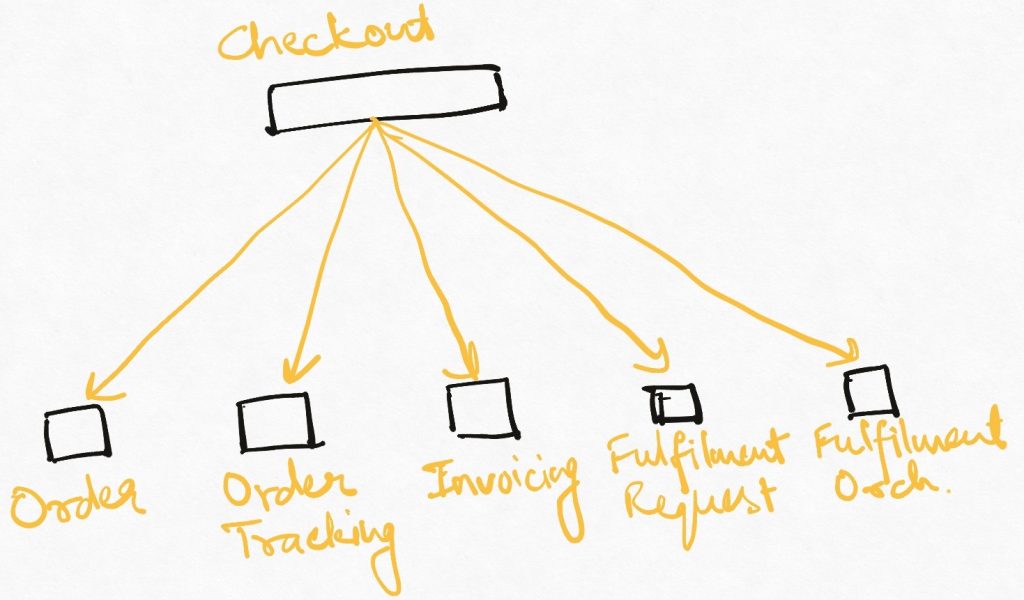
Let’s take the example of an order being created in a typical order management system. An order entity has to be created in “Order service”, tracking its fulfilment has to be started in “Order tracking service”, an invoice has to be created in “Invoicing Service”. A request to fulfil this is then sent to “Fulfilment Request Service” which invokes the actual fulfilment mechanism implemented inside “Fulfilment Orchestration Service”. The “checkout” system creating the order has to understand all of these things to understand how the order should be placed.
Let’s define two aggregate domains : Order and Warehousing. The order domain abstract the Order Service, order tracking service, and invoicing service. The warehousing domain abstracts the fulfilment request service and fulfillment orchestration service, packing service. It doesn’t matter exactly what these services do. What matters is that the two API gateways dropped in to represent the domain boundaries abstract the system creating the order (perhaps checkout service) from the multiple operations required to create an order completely. Instead, that system only sees a single createOrder(Order) interface.
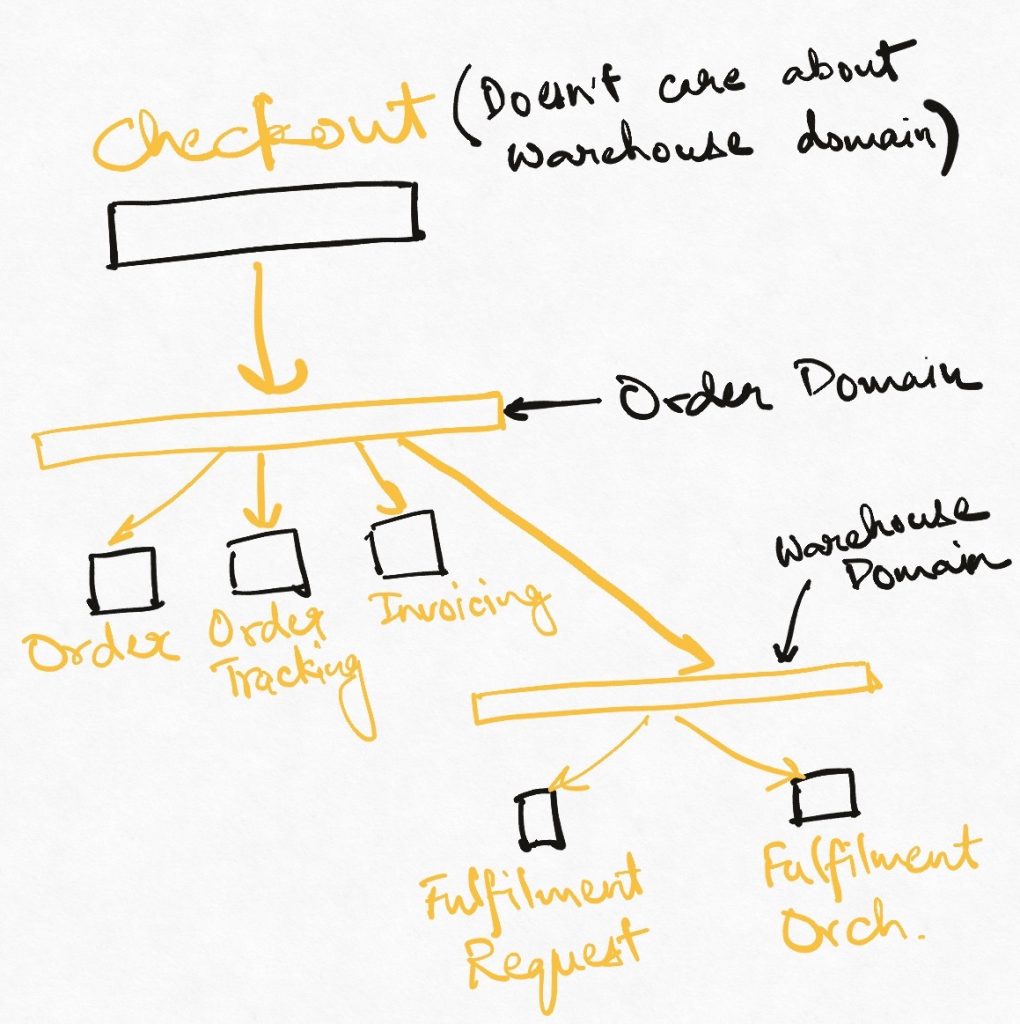
This is a massive reduction in the amount of domain language and complexity that new upstream systems have to deal with. The warehousing domain has, in fact, vanished from the view of the checkout system completely. This is the concept of layered domains at play.
Architecture informs the Organization
As you keep applying this principle to build progressively larger domains which contain smaller domains which in turn contain even smaller domains, the picture that emerges is one of how your technology capabilities are organized. This is the true representation of the technology landscape in the real world, and hopefully this is how the technology organization is set up too.
If this is not so, big red flags should be waved immediately because now you are fighting Conway’s law(“An organization ships its org chart”). If the org chart and domain models are not aligned, then somewhere, some teams are definitely struggling with massive communication overheads and friction with other teams.
So modelling domains is an exercise in organization management just as much as it is an exercise in technical decoupling.The emergent architecture of our system truly has the power to inform the structure of the organization, just as the organization structure was used to identify domain boundaries in the first place. What a beautiful, co-evolving world 🙂
Drawbacks
The biggest objection I have heard when proposing this approach is that it adds one extra network hop when crossing boundaries. This is a legitimate problem for latency sensitive applications.
However, I usually dismiss this problem in favour of the far larger problem of not being able to make sense of a large scale microservice architecture. If you have many well-defined (assumption) microservices then communication across them is anyway inevitable. Paying the one-extra-hop tax is far better than paying the I-don’t-know-which-service-to-call tax.
Conclusion
I hope this article has given you food for thought about how evolutionary and systems thinking can be applied to manage the conceptual sprawl created by microservice architecture. API gateways, or home grown “aggregator services”, or any other approach which can physically represent domain boundaries (crazy idea – separate VPNs for each domain!) can be powerful tools in defining the external as well as internal boundaries of our systems.



Very well written!
Very well written!
Awesome.
Awesome.
Very well written. For someone like me who work at boundaries of tech and business operation teams – this is like someone putting words to things i see in my organization but never too sure of what exactly is wrong and why. It was a joy to read.
Very well written. For someone like me who work at boundaries of tech and business operation teams – this is like someone putting words to things i see in my organization but never too sure of what exactly is wrong and why. It was a joy to read.
Thank god this is not on medium else we would not be able to read without a “5$ membership” 🙂
Forgot to add earlier – Very good example and agree 100% with your “Drawbacks” section.
Nicely explained the interplay of Conway’s law and cross domain modelling.
Thanks Raghavendra – I’m glad you like the argument
You can still buy me a monthly coffee on Patreon 🙂 – https://patreon.com/kislay
And it is on medium too (the only place I’m making any money as an author right now) – https://medium.com/@kislayverma/layering-domains-and-microservices-using-api-gateways-c556e01b60b2
Honestly i want to pay for a lot of good work done by authors like you BUT
1. There is no option to pay in INR (not all have US bank accounts 🙂 )
2. It should be 1 off payments rather then recurring monthly.
Maybe if there is some pateron option like that , might be easier for us to pay.