In part 1 of this series, we looked at the different types of caches and the various ways they can be used to scale up applications. Now let’s look at some nuances of using caching.
Scaling caches
Like any other part of the system design, caches come under load as the scale of the application increases. External caches are servers like any other and can buckle under the read/write traffic being sent their way. Even in-memory caches can suffer degraded performance due to read locking if too many application threads try to access them, although this is much harder to get to and easier to mitigate. let’s look at some problems and solutions scaling caches.
Scaling to more traffic
A cache is essentially a data store, and the problem of scaling for traffic is a well-known one in the database domain. Rising traffic can cause scalability problems by increasing the CPU usage or by choking the network bandwidth available to a server.
The most straightforward way to scale for an increase in traffic is to have multiple servers which can serve the traffic. In databases, we typically configure a master-slave (aka leader-follower) topology where all writes go to a single server which replicates them across all the other servers. This way, all servers have all the data and the application can connect to any of them to read them. This reduces the load on each server by a factor of the number of servers.
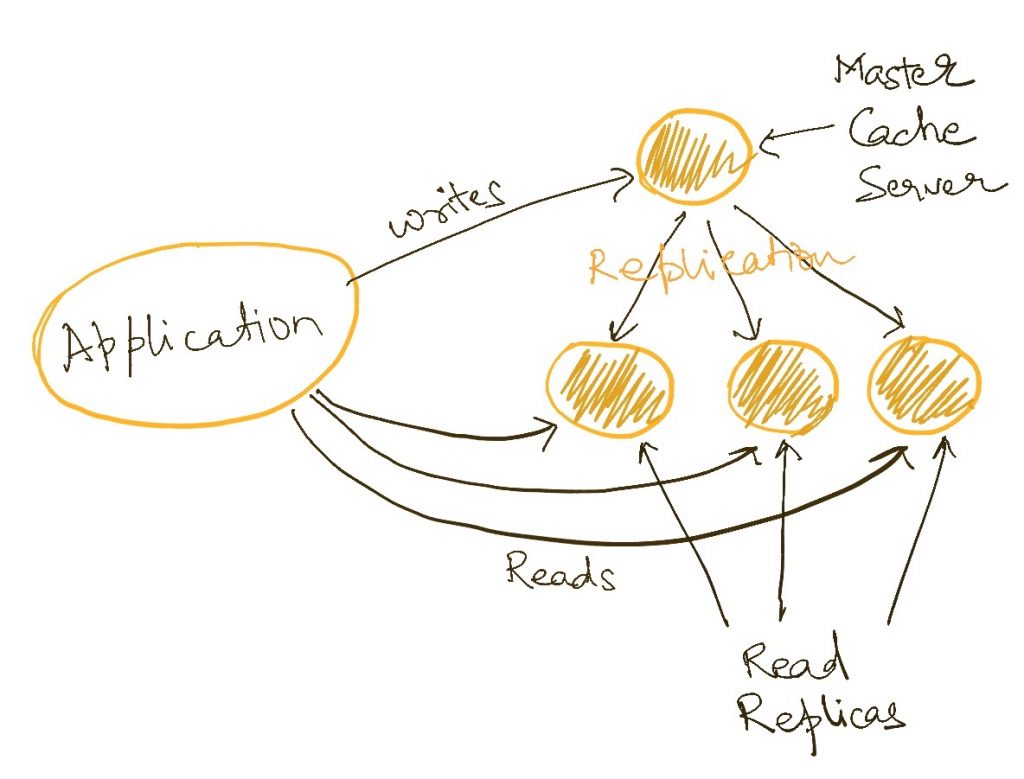
Since writes to cache data are much rarer than reads, the overhead of replicating the writes to all slave servers is usually acceptable.
Both Twemproxy and Redis Sentinel are examples of implementation which use redundancies to scale caches.
Scaling to larger data size
We have already discussed this under external distributed caches. If we want to store more data, we really don’t have a choice but to distribute it across more than one server. This directly brings the cache into the world of distributed systems with all its attendant pros and cons.
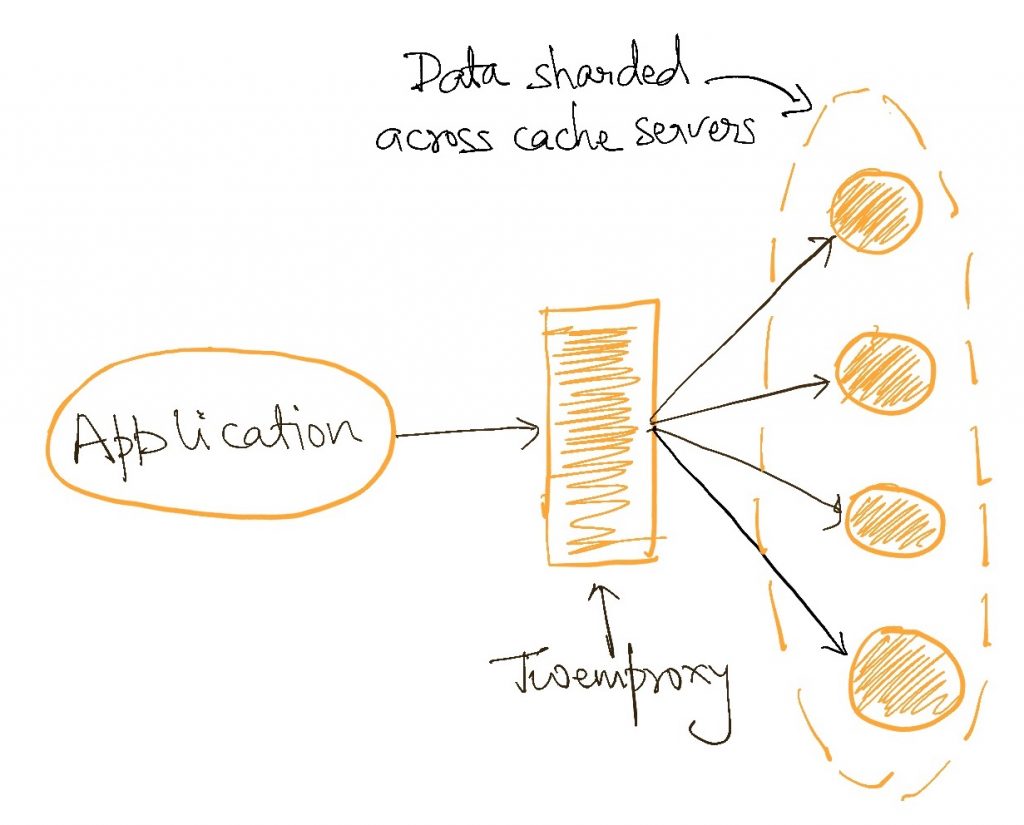
Note that distributing data across multiple servers solves for both data and traffic scaling since no single server faces as much traffic as in the case of a single cache instance. However, we can look at only doing redundant deployments if our problem is just traffic and not data volume. Data replication is a simpler problem than data distribution.
Both Twemproxy and Redis Cluster are examples of distributing data to scale to larger data volumes.
Cache Stampede
In high throughput systems, a scenario emerges in the use of caches which, if not handled properly, can bring down the entire system. This has happened to pretty much every large scale company like Facebook, Doordash, Instagram etc. I have personally encountered it while building the Promise Engine at Myntra.
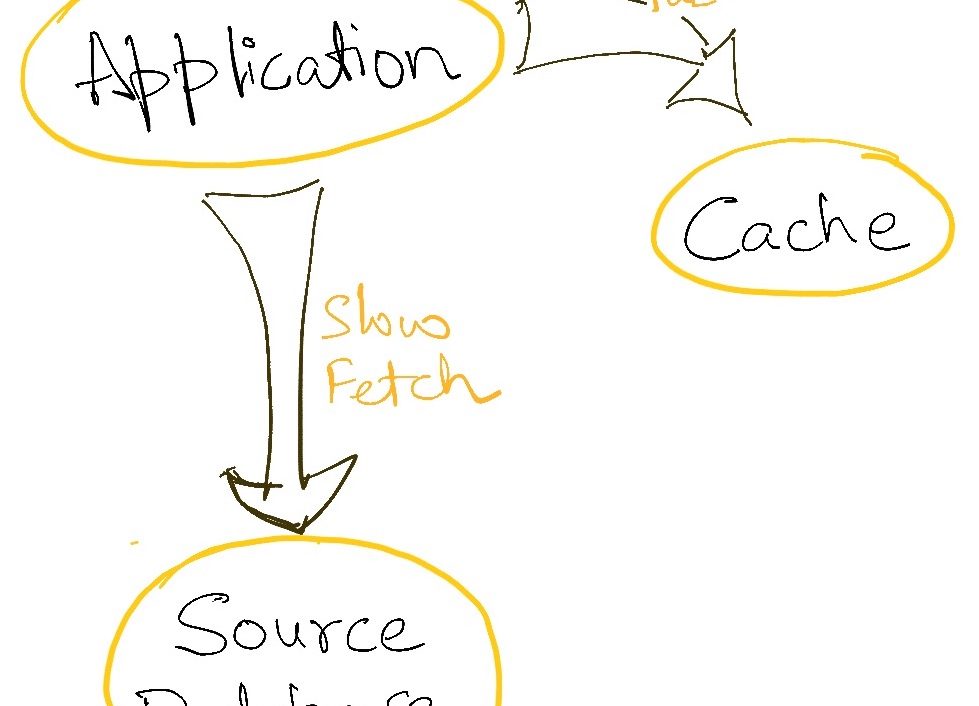
Let’s say that we are using a read-through cache where application processes first try to read data from a cache, and if not found (cache miss) they tried to load it from the source database/system. If this is a high throughput system involving a large number of concurrent accesses to the cache, then even if a single key is missing, a large number of processes will try to access the database to read this data at the same time. This now triggers a flood of traffic to the database, which may now collapse under it since it always expects a cache to sit in front of it and is not designed to take such a heavy spike of traffic.
This means that a single heavily accessed key being missing from the cache can trigger a complete system collapse. Such is the fine line of high scalability!
Prevent cache stampede
Before we try to solve the problem, please evaluate if this is a problem for your system. If your cache were to vanish and the traffic were to hit your database at once, would the database hold up with perhaps only a temporary spike in latency? If so, you do not need to worry about a cache stampede. It is worthwhile doing a simulation in your production environment to verify this.
If you think this is going to be a problem for you. there are a few approaches you can take.
Keep cache always full
This approach treats the cache as the source of truth. The idea is that since a cache stampede is triggered by a cache miss, if you can load all the data into the cache using a refresh ahead strategy, then a cache miss will never happen and hence cache stampede will be avoided.
While this is possible for small datasets, keeping large data set fully loaded at all times is not always feasible for cost reasons.
Nominate one process to fill the cache
Let’s say a cache miss occurs when 1000 processes are trying to access a key concurrently. To prevent all of them from rushing to the database, we can implement a mutex lock/leader election mechanism to elect one process which goes to the database to get the data and refresh the cache. The other processes can either wait for the cache to be filled before trying again (leading to temporarily increased latency) or they can all throw an error to their respective callers (leading to a brief spike of errors).
Obtaining locks in a distributed environment is a complicated but solved problem. Zookeeper and Redis both offer convenient ways of doing this, but you can roll your own using lock entries in a table if you think it is easier (it isn’t).
Probabilistic early expiration
This is a smarter solution than most teams require, but the idea is to balance the above two approaches. If we cannot load all the data in the cache but still want to prevent cache misses, then the only way is to reload the keys intelligently before it expires from the cache. This paper outlines one of the strategies for preemptive loading of keys before they expire.
TL;DR
Cache stampede is one instance of the new failure modes introduced into an architecture that uses caching. In designing high scale applications, this outcome of cache miss should be carefully considered before using caches.
Read Next: More articles on architecture patterns.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership

3 thoughts on “Architecture Patterns: Caching (Part-2)”