This article is contributed by Maaz Humayun. Maaz is a senior engineer at Amazon. He spent five years with Amazon Appstore working on high-volume web services that power search, ordering, and entitlements on first and third-party devices. More recently, he’s joined the Amazon Luna team, where he’s working on game-streaming tech. In his free time, he enjoys reading about SaaS platforms and new trends in software development.
You would be hard-pressed to find an industry the internet has not yet transformed. Banking, health, publishing, entertainment; the list goes on. And we’re all better off for it. Internet-enabled services are faster, cheaper, and more reliable. The only thing that’s outpaced the technological progress of the internet is our expectations of it. So you want that YouTube video to stream in 4k without buffering, no pixelation, and crystal-clear audio quality? Why, yes, I’ll have that, thanks.
The internet has gone through massive changes to keep up with growing demands. A decade ago, companies had to maintain network infrastructure and fund an IT department to keep everything working smoothly. This all changed with cloud computing. Today, all you need is a great idea and an AWS account to create a product/website that’s globally available and infinitely scalable.
Moving to the Edge
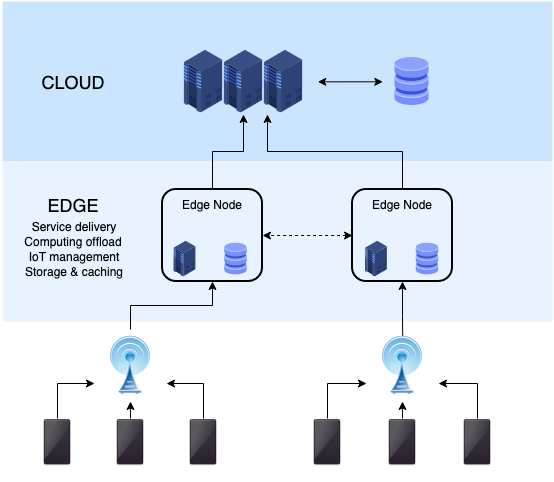
So what do we expect will change in the future? Instead of answering the question directly, let’s ask ourselves “what will stay the same?” Users will continue to expect services to get faster and cheaper. Developers will want to iterate quicker and focus their efforts on writing core business logic instead of tinkering with infrastructure. Edge computing will help us evolve the internet to satisfy these requirements.
We already use content delivery networks (CDNs) to optimize latency for applications. The concept is simple. Information can’t travel faster than the speed of light. So, to reduce latency, we need to move the data closer to the user. CDNs have several points of presence (PoPs) — also called edge locations — deployed near concentrated population centres. A CDN will cache popular content at the edge location based on customer usage patterns. If a device requests content cached at the edge, the CDN can serve the data directly, without the request going to the origin server (which could be thousands of miles away).
However, these CDNs have traditionally been very — for the lack of a better word — dumb. Customers are limited to configuring content-management policies — how and when to expire data from the cache. But a new wave of CDNs led by Cloudflare and Fastly have gone a step further by adding general-purpose compute instances at these PoPs. If you’re a developer, this means you can insert any code between the end device and your app server.
Computing at the Edge
In 2017, Cloudflare launched ‘Cloudflare Workers’, which lets customers run arbitrary code on the Cloudflare platform. Workers use Google’s high-performance V8 engine to launch V8 Isolates that execute your code. Unlike containers, Isolates are fast to spin up, which reduces cold-start time, and they are computationally cheap so you can run thousands of them on a single physical machine. To see Workers in action, watch this YouTube video which shows a developer intercepting calls to his domain and modifying the response based on the URL.
Fastly has taken a slightly different approach to serverless computing. Instead of building their compute platform on top of existing technology, they created an optimized WebAssembly compiler and runtime called Lucet. Fastly claims that Lucet can instantiate WebAssembly programs in under 5 microseconds using only a few kilobytes of memory. By comparison, Chromimum’s V8 engine has a larger memory footprint and can take 5 milliseconds to initialize programs. Fastly released Lucet as an open-source project under the Bytecode Alliance so you can check out the source-code here. Lucet already seems to be gaining adoption as a way of executing WebAssembly outside a browser environment. Shopify uses Lucet to host partner programs, called “Apps”, on top of their infrastructure. Understandably, this saves Shopify partners considerable effort because they don’t have to set up their own servers. You can read more on Shopify’s engineering blog.
Maintaining State
The Achilles heel of serverless computing has been the inability to persist data between requests. In other words, “serverless” has become synonymous with “stateless”. Sure, you can connect to a database over the network, but you must reinitialize your database connection every time you bootstrap your function. More, you need to deal with networking latency because the database and function could be running in different data centres.
Cloudflare is innovating on the data-storage front with a product called Durable Objects. A Durable Object is attachable persistent storage for your serverless function — just imagine someone plugs a pen drive into your serverless function in the cloud. Each Durable Object is globally unique and offers transactional guarantees. By co-locating the compute and data, we significantly cut down both latency and cold-start time. As you might imagine, this is well suited for real-time applications like gaming, chat, and online collaboration tools. In fact, here is a sample application that shows how you can use Workers and Durable Objects to build a simple 3D multiplayer game.
It’s also interesting to note that the serverless + storage architecture forces us to rethink our application design. In our new paradigm, the data constructs we create closely mirror our business constructs. For example, each Durable Object can maintain the state of a specific context, like a chat or document. There is no need for a centralized database that hosts data across the entire user base. Best of all, this architecture lets the edge layer transparently migrate our compute instance close to the user to optimize latency.
A natural next step and one that will pose some exciting challenges is coordination between edge nodes. Imagine a future where roads have intelligent traffic lights that have sensors to detect traffic flow in real-time. These lights could adjust the flow of traffic to avoid congestion or idle wait times. Such a system is most effective if each sensor constantly shares its data with all nearby sensors in the network. But how would we orchestrate such a system? We wouldn’t want to send all the raw data back to a central server that’s hundreds of miles away. Instead, we want all the decision making to happen at the edge. Perhaps each node is listening to data updates from all nearby nodes and making decisions independently? Alternatively, a group of nodes might elect a leader that orchestrates traffic between them, and leaders might communicate with each other through a similar mechanism. I don’t know how we’ll solve this problem, but I know it will help improve traffic.
Global Regions
Working in the cloud, we’ve grown accustomed to the idea of discrete geographical regions. Developers have to balance tradeoffs like cost and latency to decide where to deploy their applications. Want to expand to a new country? You need to deploy the entire stack to the closest region. A region-aware architecture forces developers to make decisions about geography even if their product doesn’t require it. However, the edge inverts this problem. There are no regions insofar as there is just one — “Earth”. When you deploy your code, it is deployed globally in minutes. The application is fast everywhere from day one, and you don’t pay for unused servers.
In the future, developers will have to balance yet another constraint when architecting their applications — politics. Several countries are writing laws governing data flow. For example, China has mandated that data of Chinese citizens cannot leave the mainland. Typically, this translates to companies hosting a “China stack” siloed from the rest of the world. It doesn’t require a giant leap to imagine that other countries may someday follow suit. Of course, it would be cost-prohibitive for companies to launch a new stack for each country. In a regionalized architecture, the onus is on the developer to manage the flow of data in compliance with each county’s laws. Counter-intuitively, a global architecture helps developers because we can set jurisdictional boundaries at the object level. For instance, Cloudflare allows you to set jurisdictional restrictions on Durable Objects that control where your data is stored. Remarkably, all of this is accomplished by specifying the jurisdictional restriction as a string, like so:
let id = OBJECT_NAMESPACE.newUniqueId({jurisdiction: "eu"})Where we are going?
We keep hearing about how much new data we generate each year. But let’s think about the directional flow of said data. Most data today flows from the inside-out, i.e. from the cloud to the edge. Billions of people use YouTube, Netflix, Instagram. However, most bits flow to customers consuming content. With the proliferation of IoT devices, wearables, autonomous cars, the flow of data will invert. Eventually, we’ll start to see most data flow from the edge to the cloud. Because most data will be machine-generated, it won’t all be useful. Instead of sending back terabytes of raw data to our application server, it will be more efficient to process data at the edge and only send post-processed data. Not only does this improve latency, because we’re sending less data across the network, it will also reduce costs because we’re using less network bandwidth.
As edge computing becomes more mainstream, our edge devices can become smaller and cheaper. We won’t need to ship devices with powerful hardware because the edge can do the heavy lifting. For example, a smart speaker can send raw audio to the edge server, which will strip out unnecessary bytes before sending the byte-stream to the app server. Cloudflare recently announced a partnership with Nvidia where they plan to introduce AI/ML at the edge.
For use-cases like autonomous driving, the edge creates an optimized network for cars to communicate with each other. Imagine a road with hundreds of vehicles that need to talk to each other. It would be highly inefficient for the data to flow all the way back to a centralized server, only to be received by a vehicle a few feet ahead. With an edge network, data will only travel to the closest edge node, significantly reducing latency.
Add not Subtract
The rise of edge computing and programmable networks does not mean the death of the cloud as we know it. There will always be use-cases inappropriate for the edge, like training complex ML models, storing shared user data. Both paradigms will co-exist and work in tandem, much like SQL and NoSQL today.
The future of edge computing looks promising and exciting. Already, we’re starting to see several edge computing startups try to capitalize on the coming revolution. While we can imagine all the unique ways edge computing will change the world, I suspect that the reality will be far more surprising.
References
- https://blog.cloudflare.com/serverless-performance-comparison-workers-lambda/
- https://www.youtube.com/watch?v=48NWaLkDcME&t=557s
- https://blog.cloudflare.com/introducing-workers-durable-objects/
- https://en.wikipedia.org/wiki/Software-defined_networking
- https://stratechery.com/2021/cloudflare-on-the-edge/
- https://www.cloudflare.com/en-in/press-releases/2021/cloudflare-partners-with-nvidia/
- https://blog.cloudflare.com/cloudflare-workers-unleashed/
- https://softwarestackinvesting.com/decentralization-effects/
- https://shopify.engineering/shopify-webassembly
- https://www.fastly.com/blog/announcing-lucet-fastly-native-webassembly-compiler-runtime
- https://github.com/bytecodealliance/lucet
- https://hhhypergrowth.com/what-are-edge-networks/
- https://www.youtube.com/watch?v=QdWaQOgvd-g
Read Next: The AI revolution will be unsupervised
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership



One thought on “The Rise of Edge Computing”