This is a guest post by Bharath Reddy. Bharath works for a large bank helping them with data analytics. He teaches Machine Learning and AI to people with no prior coding or mathematics experience. When not working or teaching – he can be found sketching or spending time with my dogs.
To understand what I mean by an unsupervised revolution let me first tell you a brief history of AI in 3 acts.
ACT 1
Early years 1956 – 1974
The field of AI research was founded at a workshop held on the campus of Dartmouth College during the summer of 1956.Those who attended would become the leaders of AI research for decades. Many of them predicted that a machine as intelligent as a human being would exist in no more than a generation and they were given millions of dollars to make this vision come true. [1]
First Winter 1974 -1980
Blinded by their optimism, researchers focused on so-called strong AI or general artificial intelligence (AGI) projects, attempting to build AI agents capable of problem solving, knowledge representation, learning and planning, natural language processing, perception, and motor control. This optimism helped attract significant funding into the nascent field from major players such as the Department of Defense, but the problems these researchers tackled were too ambitious and ultimately doomed to fail. Eventually, it became obvious that they had grossly underestimated the difficulty of AGI. This led to many agencies stopping the funding to this field and the difficult years that followed would later be known as “AI Winter”.
The problems
Capabilities of AI programs were limited. Even the most impressive could only handle trivial versions of the problems they were supposed to solve; all the programs were, in some sense, “toys”. AI researchers had begun to run into several fundamental limits around memory and computing power that could not be overcome in the 1970s. Most of the statistical methods which existed then, could not be applied algorithmically due to these limitations.
ACT 2
Boom 1980–1987
In the 1980s a form of AI program called “expert system ” was adopted by corporations around the world and knowledge became the focus of mainstream AI research. In those same years, the Japanese government aggressively funded AI with its fifth generation computer project.
An expert system is a program that answers questions or solves problems about a specific domain of knowledge, using logical rules that are derived from the knowledge of experts. The power of expert systems came from the expert knowledge they contained. They were part of a new direction in AI research that had been gaining ground throughout the 70s. “AI researchers were beginning to suspect— that intelligence might very well be based on the ability to use large amounts of diverse knowledge in different ways. Chess playing programs like Deep Thought were developed around this time using this prevalent paradigm.
The money returns
In 1981 Japanese government set aside $850 million for research on a large computational project, several countries responded with programs of their own. In 1982 physicist John Hopfiled was able to prove a form of neural networks (hopfield nets) could learn and process information in a completely new way. Around the same time Georfrey Hinton popularized a method of training neural networks called “back propagation”. These two discoveries led the revival of this field.
Second AI Winter 1987-1993
Desktop computers from apple and IBM had been steadily becoming cheaper and faster. They became more powerful than more expensive LISP machines. Similarly successful expert systems were proving to be too expensive to maintain. DARPA which has been a big funding source had a change of leadership, which deemed AI was not the “next big thing”. Simultaneously the spending by Japanese government did not see good returns on their projects. All of this led to the second AI winter.
Act 3
Narrow AI 1993–2011
Increase in computational power as a result of Moore’s law was effectively used with some commercial success by focusing on specific isolated problems, and pursuing that with highest standards of accountability. These successes were not due to some revolutionary new paradigm, but mostly on the application of engineering skill and on the tremendous increase in the speed and capacity of computers by the 90s. Investment and interest in AI again boomed in the first decades of the 21st century, when machine learning was successfully applied to many problems in academia and industry due to new methods, the application of powerful computer hardware, and the collection of immense data sets.
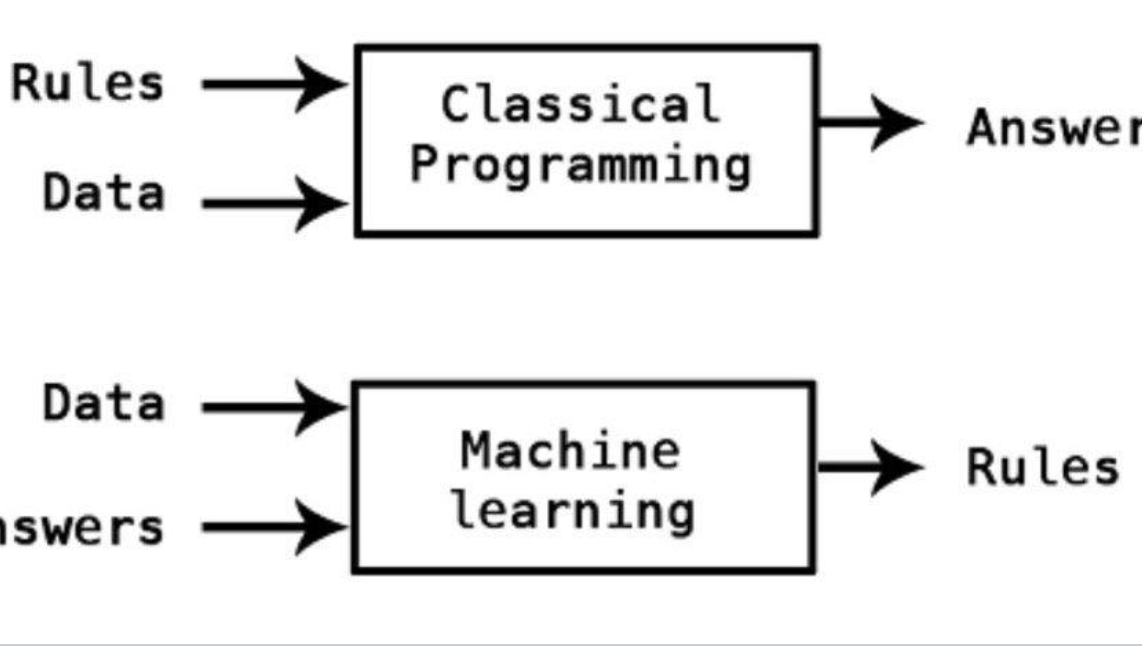
Machine learning is a sub field of artificial intelligence (AI) in which computers learn from data—usually to improve their performance on a narrowly defined task—without being explicitly programmed. – 1959 Arthur Samuel.
DEEP LEARNING BECOMES FEASIBLE 2011
Deep learning is a branch of machine learning that models high level abstractions in data by using a deep graph with many processing layers. A couple of neurons can now approximate any mathematical function. State-of-the-art deep neural network architectures can sometimes even rival human accuracy in fields like computer vision, specifically on things like the MNIST database, and traffic sign recognition.
AI has re-emerged with a vengeance over the past two decades—first as an academic area of interest and now as a full-blown field attracting the brightest minds at both universities and corporations. 3 main drivers for this
- Focus on specific tasks rather than general AI.
- Tremendous increase in compute power, the most recent RTX card has 10 Mil times compute power than the one MIT labs had back when hopfiled came out with his network.
- Data availability: Over the last 10 years we have had a million fold increase in the number of datasets which have been curated and made public.
AI is now viewed as a breakthrough technology, akin to the advent of computers, that will have a significant impact on every single industry over the next decade.
Of course, these successes in applying AI to narrowly defined problems is just a starting point, and the hope is that by combining several weak AI systems, we have a good shot at developing strong AI. This strong AI will be capable of human-level performance at many broadly defined tasks.
The Next Revolution
If you have followed the history of AI, you might have noticed a pattern.
- Solution to a big challenge was attempted (AGI) – but failed,
- AGI was broken to narrow set of problems (weak AI)
- This have been solved mostly using large amounts of data.
Most of the successful commercial applications to date—in areas such as natural Language processing , computer vision, speech recognition, and translation, have involved supervised learning, taking advantage of labeled datasets. However, most of the world’s data is unlabelled.
The field of machine learning has two major branches—supervised learning and unsupervised learning and a few others but those are not of interest for our discussion. In supervised learning, the AI has access to labels, which it can use to improve its performance on some task. Supervised learning excels at optimizing performance in well-defined tasks with plenty of labels.
Most of the problems that have been tackled by Machine learning today are by using supervised learning, in this method AI trains on data and measures its performance by comparing its prediction to what is true data. This is why labels are so powerful, they guide the AI agent by providing it a measure of error which the AI agent minimizes. Without these Labels AI has no measure of how successful it is.
Increasingly we have tackled problems of increasing complexity by throwing more data at AI/ML models – this gives more features and more labels and we have ever faster computers available. We have already reached a stage where all the state of art algorithms are trained on datasets big enough to fill a couple of data centers and trained on millions of Compute units.
So What are the problems with this ?
Supervised AI advances are dependent on resources now.
Supervised AI trains on some data it is fed however what we care about most is how well the AI generalizes it training to never seen data before. To ensure AI generalizes well, we have to feed the AI , increasingly large amounts of labeled data – and this is how increasingly AI has advanced – by gathering larger and larger “labeled “ datasets. Increasingly we have tackled problems of increasing complexity by throwing more data at AI/ML models – this gives more features and more labels and we have ever faster computers available. We have already reached a stage where all the state of art algorithms are trained on datasets big enough to fill a couple of data centers and are trained on millions of Compute units.
Today, most of the Supervised AI breakthroughs depend on ability to get large labeled datasets and vast compute power. Both of which, rich organizations have in plenty and hence we see most of the breakthroughs coming from places like – Google, nvidea, MIT ,Facebook, Tesla etc.
Supervised AI generalizes only on data it has seen.
Lets say at some point in time we reach a stage where everyone has access to all the data – still the learning of Supervised AI would be limited to what it has seen. Highly anthropomorphic learning I would say. Regardless of how highly trained a supervised AI is – it would not do well in conditions it has never seen before. This is akin to training someone in classical physics all their life and expecting them to understand quantum nature of things. Or training someone to swim and expecting them to execute a good space walk.
Supervised learning excels at optimizing performance in well-defined tasks with plenty of labels and would trounce unsupervised learning at narrowly defined tasks for which we have well-defined patters that do not change much over time. However Unsupervised learning makes previously intractable problems more solvable and is much more nimble at finding hidden patterns both in the historical data that is available for training and in future data. Moreover, we now have an AI approach for the huge troves of unlabeled data that exist in the world.
Even though unsupervised learning is less adept than supervised learning at solving specific, narrowly defined problems, it is better at tackling more open-ended problems of the strong AI type and at generalizing this knowledge problems where patterns are unknown or constantly changing, for which we do not have enough understanding or large labeled datasets – our hope lies with unsupervised learning.
No new paradigm
The backbone of current supervised learning is to some extent – a single algorithm – Gradient Dissent. Now this algorithm can do only so much and has its own limitations. Finding a way around these limitations was by adopting increasingly novel and complex architectures. But in essence this is like having a knife and we keep changing the shape of it and sharpening it – but a true advancement would be someone discovering chemical properties and inventing a gun.
Refinements of a knife is akin to progressing in same generation, discovery of chemical properties and invention of a gun – Leap to next generation.
Refinements to accuracy of a gun is progressing in same generation, discovery of nuclear power and exploiting it is akin to leap to next generation.
By same analogy we need to think beyond supervised AI for the leap to next generation.
Curse of Dimensionality
The fundamental way in which data is represented in a mathematical form which computers can work on is by projecting each feature of data as a dimension. For ex datasets with your height , weight, age , Blood pressure and cholesterol level would be represented with x axis as height, y axis as weight, z axis as age, and then our comprehension fails us – we cannot fathom things beyond 3 dimensions, however a machine adds more axises and each feature is represented as an axis and any dataset is represented as a point in n-dimensional graph. Now it so happens that as the number of features grows , our dimensions grow as well and as these grow, the distance between each points tends to infinite and mathematically it can be proven that the space between all the points also tends to infinite and the entire data looses its notion of similarity and dissimilarity of any two observations. This is called curse of dimensionality. Our existing supervised algorithms break down at this point. For more physics oriented amongst you think of think as singularity where all equations break down.
Unsupervised Learning is well suited to help manage this by finding most salient features in original dataset and reduce the number of dimensions to a more manageable number while losing very little information in the process.
How does Unsupervised Learning work ?
Unsupervised learning works by learning the underlying structure of the data it has trained on. It does this by trying to represent the data with a set of parameters that is significantly different than the number of examples available in the dataset. By performing this representation learning, unsupervised learning is able to identify distinct patterns in the dataset and capture the essence of data.
Unsupervised learning makes previously intractable problems more solvable and is much more nimble at finding hidden patterns. Though not as adept as supervised learning at narrowly defined tasks, unsupervised learning is better at tackling more open-ended problems of the strong AI type and at generalizing this knowledge.
Take a toy example – email spam filter problem, we have a dataset of emails with all the text within each email labelled spam or not . In unsupervised learning, labels are not available. Therefore, the task of the AI is not well-defined, and performance cannot be so clearly measured. Now, the AI will attempt to understand the underlying structure of emails, separating the database of emails into different groups such that emails within a group are similar to each other but different from emails in other groups.This unsupervised learning problem is less clearly defined than the supervised learning problem and harder for the AI agent to solve. But, the solution is more powerful.
The unsupervised AI may find groups which can be categorized as “work” , “friends”, ”promotions”,”spam” etc. AI agent may find interesting patterns above and beyond what we were initially looking for.
This is how the human brain works, we are taught a few things like how a hot object burns (labels) but our understanding of the world is not just a sum total of all our memory of labels. Imagine having to take a decision after running through all your memory of what object is hot and what is not!.
Our brains have developed some heuristics as survival / evolutionary traits. We have also developed a notion of abstraction – a higher form of knowledge if you will. This means in general hot things would burn, this might be gas stove, embers , running engines etc. And some events cause things to get hot like, being in the sun for a long time, being burnt, being in contact with other hot objects etc.
In essence our brain is doing exactly what an unsupervised learning agent does – finding patterns and associating experiences to each pattern and solidifying these into notions about those things.
For the same reasons I am of opinion that – unsupervised learning is the next frontier in AI and may hold the key to AGI.
The next AI revolution may well be unsupervised!
Read Next – ML will be an indispensable part of this decade’s full stack team.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership