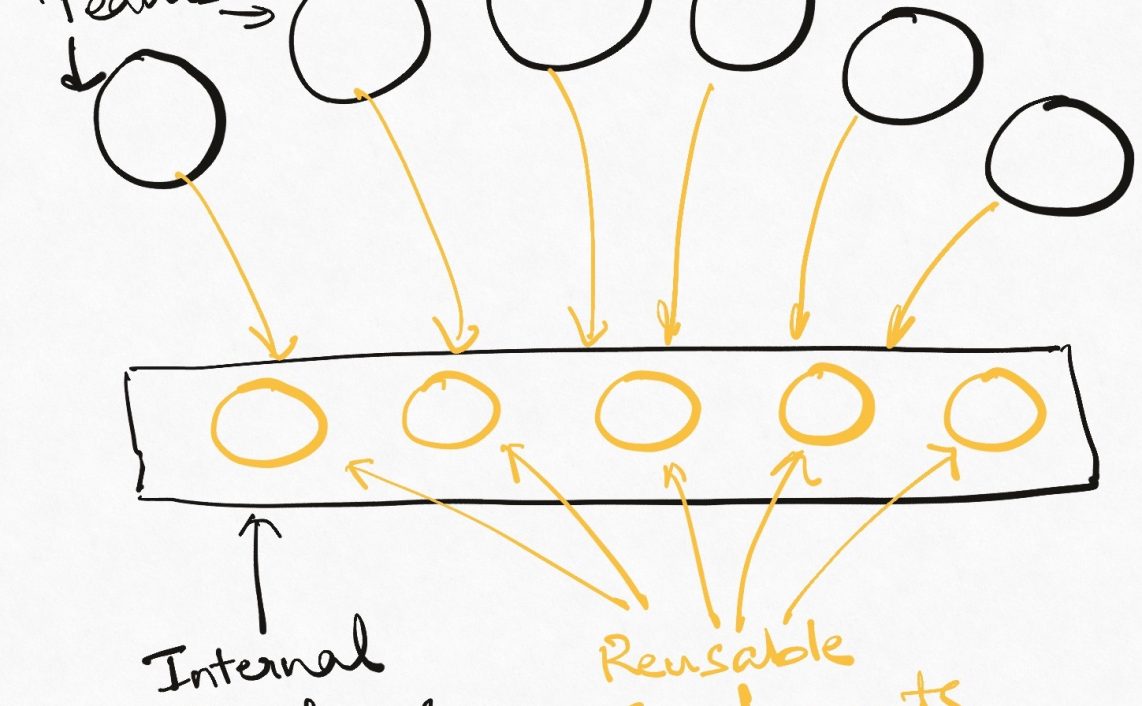
Have you heard of the “full stack team”? Odds are that you have – it is the cornerstone of the agile methodology that is very much in vogue these days. A full stack team is a self-contained, autonomous team whose members collectively have all the skills needed to solve the problem they have been set upon. Such a team can build backends and APIs, manage its own data stores (for all practical purposes), and build its own UIs/frontends – thereby removing any need of dependency on other teams for fulfilling its mission. These teams are now found all over the industry, and limiting the lines of communication and co-locating the skills in this way has turned out very well in general. aka Two-Pizza team.

In the coming decade, a full-stack team is going to require two more critical skills to remain full-stack. These are data engineering and data analysis/machine learning.
What are these things
Business Intelligence and Reporting (BI) has historically been an independent function and team, separate from the more “operational” teams which own the software that runs the business. The latter generates business data (customer, orders, invoices, bookings whatever) and the former uses this data to generate insights into the business (RoI, TAT, personalization, margins across different dimensions etc). This would typically be done by shipping all the operational data into a “data lake”, and then unleashing specialized analysts upon this vast trove of data to do all sort of slicing and dicing. The outcomes from this analysis would flow out to organization leaders, then back to operational teams as the next set of features they had to build – thereby completing the feedback loop.
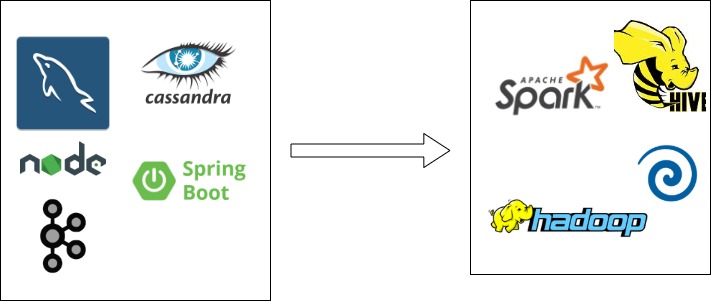
The organizational divide mirrors the technological divide. Frontline teams use “OLTP” data storage and build high-performance systems to please the customers of the business directly. Microservices, sub-second latencies, asynchronous messaging, and the latest UI frameworks feature prominently in the discussions of these teams. BI teams focus nearly exclusively on moving large amounts of data around using frameworks like Pentaho, Spark, etc, joining data from all over the organization into “OLAP” stores like Hadoop, Hive, Amazon Redshift, etc, and catering to the analytical requirements of internal customers like business analysts and data scientists.
Why touch what ain’t broke?
There are two main reasons why these worlds are now converging, and they tie in neatly with the distinctions mentioned above.
Centralized BI is a bottleneck
There are two kinds of analyses a BI team usually does. One is deep-dive into business data to derive insights into what the business is doing and what can be done to move it forward. The other is a more mundane, operational type of reporting around revenue, operational business metrics, monitoring the impact of some features being rolled out, etc. While the former type seems like the place where ML/AI etc would belong, they are being increasingly used in the latter type of analysis as well.
As an organization grows, the latter type usually grows so much that the former begins to suffer and a centralized BI team becomes a bottleneck in running the business. The feedback loop I described above starts to get too slow for the modern agile organization. Look at what is happening on the OLTP side. We are creating small teams and giving them greater and greater freedom to execute on independent roadmaps using their favourite technologies and microservices architectures. But on the BI side, the complexity is becoming greater and greater as the BI team struggles to keep up with a faster rate of external change. As an organization scales, it is near impossible for a central team to manage all this data, understand it, and give meaningful insights unless at least some of the workload is taken off. The most straight forward of doing this is to move some of the operational data responsibilities back to the OLTP teams. This organizational single responsibility principle would vest all operational capabilities (including data management and analysis) in the operational teams and deeper analytical work in the erstwhile business intelligence team, who now become just some external consumers of the business data, not sitting in the line of business.
But how is this to be done, considering the technical chasm between these teams? Fortunately, there is good news on that front as well.
Technical Choices are converging
As the hunger for “real-time everything” expands across the board, the tools and technologies used by the BI and operational teams are beginning to converge. Instead of the clunky batch jobs of old, more and more data is moving over messaging systems like Kafka. These data streams can be processed equally well by asynchronous microservices for interprocess communication or by tools like Flink and Spark for computational and analytics. As the technology lines blur, a data engineer with specific business domain knowledge in, let’s say, warehousing and shipping, can use his existing tool-kit do a lot of analytics and reporting from within the operational system boundary. In a sense, we can now expand the bounded context of our services to included analytics as well.
Additionally, the use of big data is becoming more and more commonplace and “familiar”. Writing a data pipeline is like writing just any other kind of code, albeit one that has a different set of requirements. As developers get more and more access to commoditized/managed versions of big data platforms, it only makes sense that the data production and data analysis are getting more localized.
Similar logic applies to the machine learning eco-system. The technology eco-system is becoming more mature, and the big companies are open-sourcing their internal infrastructure. AI/ML engineers have long bemoaned that data is the biggest challenge for them – and it makes sense that as data manages goes into the of individual teams, so can the use the use of this data for use in ML models etc.
I’m not suggesting that deep research work or cross-domain data crunching will be subsumed within our two-pizza teams. There will always be a huge number of cases where uses of specific technologies and data sets will require teams sitting outside operational boundaries going niche work with niche skill-sets. However, I expect basic (definition of basic varying from company to company) competency in data processing and analysis to become part and parcel of every developer’s and every team’s bread and butter. Gone are the days when developers could toss their data over an ETL wall and call it a day.
I believe this is a good thing.
Teams that can own their data and process/analyze it to understand their business will be able to bring greater value to the business as compared to the teams that cannot. Consequently, they will retain more of their autonomy and agility in a world where data is quickly becoming king (if it isn’t already). They are also likely to move faster since they have removed an external team’s dependency from their go-to-market path. If you are looking to scale your organization and team in this decade, I would say that providing your developers with these skills and tools should be among your top priorities.
The biggest problem I see in this path is recruitment. In the early days of autonomous teams (and even now), a DBA was always too scarce a resource to commit entirely to a small team. They were often shared among multiple teams. Similar will be the case with ML engineers – there just aren’t enough of them – despite it being the most sought-after field for students. Hence for some time at least I expect that ML/AI engineers will be a shared, precious resource among multiple teams and a source of much political footwork among managers.