End-to-end testing refers to the approach of testing every step of every single user flow. e.g. In the e-commerce domain, this might mean testing every API call and database write/read from the moment an order is placed to the moment it is delivered. The end-to-end testing process will validate every notification sent to the customer, every tool used by the ground force, and every third-party interaction involved. This testing paradigm validates the end-user experience by validating behaviour across multiple domain boundaries and teams.
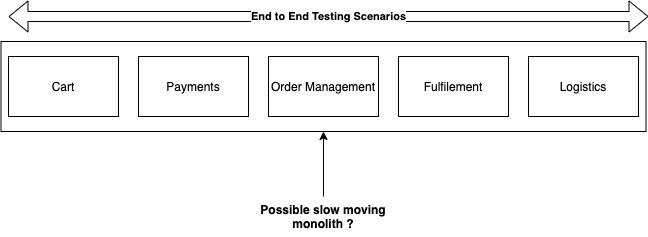
Back when all systems were monolithic, development batch-y, and releases infrequent, this was the de-facto approach for testing software before it was released. It made perfect sense because if the last release was some time ago and many features were being developed, it was quite possible that many parts of the codebase had changed simultaneously.
Sadly, end-to-end testing has persisted in the modern microservice architectures as well where it adds very little value and creates a massive roadblock in attaining a high speed of development and deployment of software. Especially if an organization follows agile principles and ships code quickly using CI/CD etc, this approach of testing can bring the entire delivery pipeline to a standstill. Let’s see how we can do better in the microservice world.
There are two main technical advantages that microservice architecture gives us. The first is independent services which can be developed, deployed, and scaled independently. The second is that relationships between these services are now explicit and the dependencies trackable.
The first means that at an organizational level, there is no longer a single artifact to release at a certain fixed time/cadence. All services change at their own pace. The second means that only a small subset of the overall system is impacted when any of the services deploy a change. It is easier to identify what impacts what in microservice architecture (if it is well designed).
The end-to-end testing mindset focuses on the idea that since there are now many things, any of which can cause a problem, we must test all systems/features before we deploy anything. It therefore completely surrenders the second advantage of microservice architecture – identifiable dependencies. And by ceding this advantage, it becomes a blocker to agility rather than an enabler.
It can be argued that this is not a microservice-monolith question but rather a slow/fast shipping question. In a slow shipping monolith/microservice, it is difficult to establish what the immediate neighbours are because many changes are being deployed together. If each deployment consists of a single change, then it is easy for devs and tester to establish what should be tested. I feel that microservices simplify this further by making the separation of concerns even more explicit or externalized.
We don’t need to test everything all the time. Looking at the service which changed, we can isolate all services that interact with it, and test only the interactions with them. If system boundaries are drawn well, only the immediate neighbours should be impacted by any change.
So how should agile organizations test a microservice-based architecture?
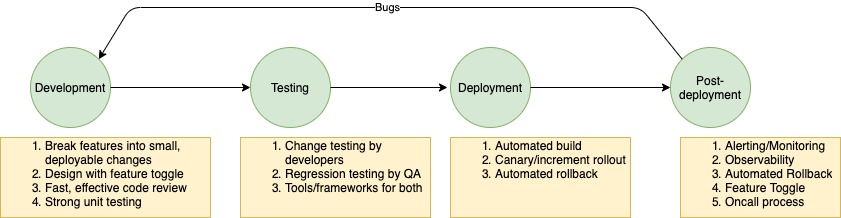
I prefer a two-pronged approach, both of which assume automated integration testing ability. If you are still doing full manual, you need to get in the automation game ASAP.
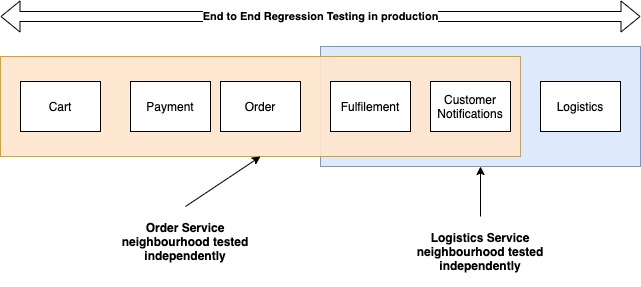
First, we need to speed up the testing of each service or component so that our independent teams can move fast. We need the ability to identify all its immediate neighbours and verify that all those interactions are working properly after the change. If service A is changing, then immediate neighbour means every service that service A calls and every service that calls service A (or consumes events from service A). So both upstream and downstream systems constitute a service’s neighborhood. Only the neighbourhood of a component has to validated in order to safely deploy changes. This reduced scope of testing makes the whole process faster.
Identification of a service’s neighborhood can be automated (eg. using a service mesh/request tracing to extract who calls who) or manual. Once identified, we can use techniques like CDC (Consumer-Driven Contract) Testing to verify that every interaction of the service under test is working fine. Many organizations also tag/group integration tests to be able to run subsets of integration tests for further optimization (e.g. if only API 1 is changing, only run tests related to that in the immediate neighborhood).
The more widely used a service is, the larger its neighborhood will be, and hence the greater the amount of testing that needs to be done. While this means that deployments of this service won’t be as fast, it also makes sense that the most used services should move slowly to prevent big outages. As long as the whole process after merging to main is automated, who cares anyway 🙂
But the optimization in testing each service that we have done (we aren’t testing everything all the time anymore) means that some unknown unknowns can cause bugs to slip through. So the second prong of our testing strategy is to continuously run integration tests on all critical customer-facing features in production. This can be automated tests against our public API, selenium style tests against the UI, or anything else which can flag any behaviour unexpected by the customer. If an anomaly is detected here, we raise a bug which the relevant dev team then takes over to investigate and fix.
The latter set of tests should be put in place first – in fact, these should be considered part of a feature release. This is yet another argument for developers writing integration tests. A post facto QA team/process can’t hope to keep up with a fast-moving developer team. The organization should focus on enabling dev-driven testing by giving them time to do it and setting up the tools to make writing tests easy. Dev teams can then focus on building and testing their features.
Move as fast as you can, and break as little as you can help it!
Read Next: Events, not logs are the right paradigm for Observability
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership