The whole theme of the last decade or so (maybe more) has been about agility and techniques that enable agility. CI-CD, DevOps etc have become a critical feature of this, and yet I often see a lot of friction when it comes to deploying. There is a magical aura around deployment which makes it something special, and this impacts how many of our teams work in each of delivering software.
Why deploy fast
No matter how beautiful our system architecture, how elegant our code, and how solid our test suite – the only way we get to make an impact on our business and our customer’s lives is when we actually deploy code to production. Before deployment, code is just an intellectual exercise, like an interview question. Deployment turns this intellectual property into an economic proposition. So it seems like a no-brainer that we should be deploying code as fast as possible.
And yet engineering orgs struggle with this activity. It is a documented fact that the overwhelming majority of outages are a result of new changes deployed. This makes sense – if nothing changes, then things are far less likely to break down. So deploying code has obvious risks.
Most of the currently popular engineering practices are aimed at increasing the rate of software deployment while mitigating the risk of failure arising from this increased rate. Pretty much anything works at small scale and companies, but as the scale of the enterprise grows in terms of software or team size, context becomes increasingly important, and reverse engineering from development back to design/implementation can expose a lot of inefficiencies.
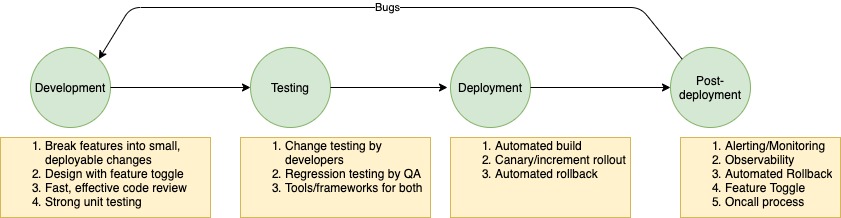
If we agree that deploying software fast with high quality is a worthy goal, then I want to apply a pipeline-like perspective to the process of delivering software so that we can identify bottlenecks and broaden them to make the process more efficient. Applying the Theory of Constraints means that we model the software delivery flow in reverse, identify the bottlenecks, and optimize them one after another.
Deployment causes outages
This is the most widespread argument against deploying changes to production and as I mentioned above, industry data supports this. It has therefore become the flagship argument for treating deployment as some type of sacred activity. However, there is a lot of subtext to this top-level problem that merits looking into.
While this is a whole universe of topics in its own right and includes multiple disciplines, I want to call out that if fast and safe deployments are the desired objectives, then we cannot do without efficient means of :
- Discovering when things go wrong – To reduce outages, we need to be able to detect them. Observability tools are indispensable for this, and automated tests running in production as very effective too. We need these tools regardless of whether we deploy frequently or not, so we might as well go ahead full steam and reap the benefits! Additionally, the organization should have dependable on-call support protocols (preferably manned by developers, but at least by some sort of central ops team) to respond to alerts.
- Mitigating the problem – Since we are talking about outages caused by deployments, the most powerful tool we have for mitigating the problem are canary deployments and automated rollbacks. Coupled with monitoring tools, they give a pretty solid safety net for when things go wrong. Feature gates are another extremely powerful tool to manage deployment risk. They allow us to deploy code that can later be engaged under close supervision instead of having every change going into effect as soon as it is deployed.
- Debugging the problem – Whether you like the logs-metrics-traces approach to observability or the event-based approach recently gaining ground, you need tools that allow your team to rapidly nail down the cause of the problem. Without these, you will be helpless even in the face of known problems because you won’t know where they stem from and why.
- Fixing the problem – Once the problem has been identified, product and development teams need to have processes that let them determine the priority for the fix and get the fix out of the door as quickly as possible. Note that the ability to deploy a bug fix fast is contingent on our ability to deploy ANYTHING fast.
Deployment takes time
Before we dig into the specific, I would like to point out that thanks to feature toggles, deployment is not release. Code for a feature may get deployed without coming effect because it is toggled off – this will become relevant below.
Let’s consider the actual process of deployment. Some teams I have worked with in the past have argued against deploying often because deployment takes up a lot of time from the team. Here again, we can look at the various steps typically involved and identify the ways in which they can be made efficient.
- Merge all the code to the deployment branch – This is often, but not always, done by the engineer who happens to be on the hook for deploying the application (for whatever reason) – and it shouldn’t be. Merging code to the deployment branch is part of the development cycle but often becomes part of the deployment cycle because any code sitting in the deployment branch becomes “active” when deployed. This dependency can be broken by using feature toggles as mentioned above. Developers should merge code with appropriate implementation of feature toggles.
- Trigger and monitor deployment – While the gold standard of all of this is CI-CD process,, a good enough compromise (IMO) is an automated deployment process which includes building the deployment branch, running automated sanity/integration tests, canary deployment with auto rollback followed by rolling/incremental deployment. While this might take time depending on the infrastructure being used, it should not be a hands on activity for the dev team. They should get actively involved only if they see failures.
- Validate that system is stable post deployment – This is essentially the activity of detecting and debugging outages in production when caused by deployment and we have already discussed techniques to make this efficient. Another aspect here is the actual release of the code that was shipped (remember – deployment is not release). Release should be the responsibility of individual feature developers and they should judge when they should use feature toggles to expose their code to its users. As such, this is not a process of the deployment cycle.
Testing takes time
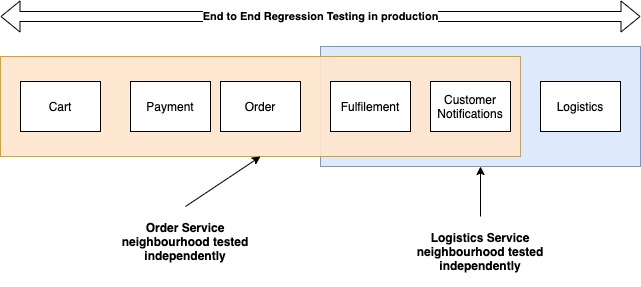
When I was working in the supply chain team at Myntra, we had this practice of testing end-to-end. This meant that a feature (any feature) could be considered signed off by QA only if we could make a whole set of orders of different types all the way from the customer cart to logistics. With testing environments being broken often due to untested code, needless to say, sign-offs were a bitch, both for devs (too slow) and for testers (too painful). Widening the testing bottleneck typically means working on two fronts:
- Testing individual changes – Since we are trying to deploy fast – it means that changes will be coming in fast, and each complete feature might involve changes to multiple teams and systems. Having a QA handoff on this path is extremely inefficient. I believe testing of individual changes is part of the development process. Whether by unit testing, or automated/manual integration tests, developers should verify their changes are safe to deploy and functioning as intended (including feature toggles). Consumer Driven Contracts are a powerful tool in testing small changes and individual components that I am surprised are not very popular.
- Testing complete features – This is the testing of the complete customer experience, and this is something that QA teams can own and drive using rigorous automation. While this is an important component of testing, it should be understood that this is a process parallel to the mainline software delivery path and will always run slightly (and only slightly) behind the latest production system (we had put it inside the delivery path at Myntra because, at the time, we were not doing a good job with testing individual changes). It is however, very powerful in detecting regressions and also acts as a repository of information about how the system is expected to function.
Splitting these two tracks and making separate teams responsible for both significantly broaden the testing bottleneck.
We deploy complete features
Feature development often works as a batch process. Developers design for the complete feature, and then implement the complete design in one go. In a way, the complete feature becomes the unit of work for developers. This is okay for features of trivial size, but when we work on large features which touch many parts and layers of an application, this style of working creates a huge risk because multiple developers are doing the same thing. If all the changes come together just before deployment, there will be tons of conflicts and it is difficult to predict if all features are still working correctly.
I’m not even talking about the agile process of identifying sprint stories – this is an even lower level than that. If a code change makes sense on its own (e.g. schema changes to create a new table in a database, core business logic that is not yet exposed via an API), what stops us from deploying it? By holding it back, we are causing two problems:
- Our teammates working in the same areas of code haven’t seen our changes – we may be stepping on each other’s toes. Getting small changes out there quickly avoids confusion later.
- If the change is logical and deployable, then why NOT deploy it? After all, the larger the deployment, the larger the risk of things breaking on deployment.
However, there are certain prerequisites to be able to implement features in small bites.
- Design large to implement small: We spoke earlier about how treating the entire feature as the unit of work can be troublesome. However, to be able to break down work into smaller units, we need to design (at least roughly) the entire feature. This is necessary to make all the small pieces fit correctly. The output can look something like this – “we need a table to store these data points, REST APIs to insert single and bulk records to this table, and integration with external service X to check for Y before we insert”. We identify coarse-grained system boundaries that the feature implementation will impact and identify the changes that will be made. Coarse-grained is a relative term here, and this is a recursive process – if the feature is very large and spans multiple systems then we have to keep applying this breakdown till we reach the code if actual code that will be written in each of those systems.
- Test small changes deeply – Since each change is small, developers should be able to establish easily that each of them works exactly as intended. The fastest mechanism for doing this is via unit tests that mock external dependencies. However, any mechanism is fine as long as it establishes the deployment safety and intended behaviour of the change being published. Code reviews should look out for these tests.
- Small, fast-moving code reviews: One feature need not travel as one pull request. As a result of our design exercise, we can now implement the feature in a series of very small pull/code review requests in line with the design boundaries defined above. Large pull requests are never going to get reviewed as thoroughly as small ones because they take a much larger amount of effort on the part of the reviewer. The flip side of this argument is that we should have team processes in place to get the code reviewed very quickly. I have published some guidelines for reviewing distributed systems code – check them out for some pointers on things to look out for.
After these changes, we are pushing very small, verified to be safe changes down the deployment pipeline, much of which is already automated and needs minimal manual intervention. But no amount of automation or tooling will help make our deployments fast or safe if we insist on pushing large changes in batches. Large change sets lead to poor testing/reviews lead to unstable systems.
Software Delivery as Change Stream
To me, this is a mental shift in terms of thinking of software delivery as a stream of small changes that are intended to compose into a feature on deployment instead of thinking in terms of moving features from the developer’s laptop to production servers. There is no such thing as a feature that is “done” – everything is always evolving and changing. So instead of viewing features as statically-bound things that we ship, we should think of them as a set of changes that we need to make within certain system boundaries. Some people call this ”Flow” of work through software organizations. This is enabled as much by the adoption of agile techniques in the development phase as it is enabled by evolving out-of-the-box infrastructure capabilities in the deployment and operations phase.
TL;DR
Deploy as frequently as you can. No matter what you think the cost of deploying is now, it will only be greater later on. Unless you are building some life-or-death related software or something which is highly regulated, my vote goes to deploying as fast as you can. Like the broken-window theory, making rapid deployment an engineering objective will directly give rise to a robust engineering culture and practices which will help your organization in the long run.
Read Next – Moving faster (not just fast) as an organization imperative (aka Build momentum not velocity)
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership