I got a lot of feedback and support on my article about thinking in terms of events instead of messages when thinking about logs. Charity Majors herself gave a shout out – so yeah I had a good week 🙂
I am no expert on Observability or tech operations so I try not to write much about it. However, a lot of people raised some concerns enough times that I felt some more clarification was needed. In this article I will try to address some of these confusions.
Logs are for debugging
Several people pointed out that logs are critical for debugging issues in code. When some piece of code is malfunctioning, it is important to be able to trace the execution of this code step by step to determine exactly what is going on in there. Logs are very useful for this, and therefore logs cannot only be about events at boundaries as I had expressed.
I view logs with two different perspectives as they are used today. One type of logs are used for observability, and the other are used for debugging. I have no problem with the latter, and I agree that it is important to have these. What I disagree with is the conflation of the two.
Observability is a study of the system in motion. We observe the system “from the outside” as it goes about its business. If we have good mechanisms for observability in place, we can tell which parts of the system are working well and which are facing problems. This worldview has certain direct implications. It presupposes that we can identify “parts” of a system (hence my insistence on boundaries), and that we know what it looks like when these parts are not working well (hence the insistence on observing events at boundaries instead of “everything”). We don’t observe to debug – we observe to understand and identify system behaviour.
Observing the system in motion also means that we are observing a stream of things as they happen. The only way to make sense of streams is to keep a history of them and work with aggregates. This means, almost by definition, that we need event processing systems to understand what is going on. It is unrealistic to expect humans to operate at this scale by watching logs. So observability based constructs should be aimed towards capturing as much aggregate information as possible and processing it to determine outliers.
Debugging on the other hand, is about the system at rest. When we know the whereabouts of a problem, we pause the entire system (that’s exactly the job of a breakpoint in a debugger) and try to isolate the exact problem with specific inputs and scenarios. This is a one-off deep dive, and human expertise is inevitably required here since the system cannot infer the why of its own internals.
Logs can be helpful here, but there are plenty of other ways of doing it once we know exactly which parts of the system are malfunctioning. Unit tests are meant for exactly this behaviour – isolate (mock) the externalities and test the system to verify what it does. Logging is one way of doing this, and arguably not the best way.
I object to putting ad-hoc strings in Elasticsearch or files as an observability mechanism. It is chaotic at best, and misleading on average. The lack of structure in logging directly gives rise to the need for the other “pillars” of observability – logs are just not enough in their current form.
By all means use logs to trace specific parts of a program, but think of this as a separate activity than identifying system boundaries and behaviours. Conflating fine grained debugging with coarse grained behaviours is fundamentally inefficient.
Logs and Metrics combine to give full operational coverage
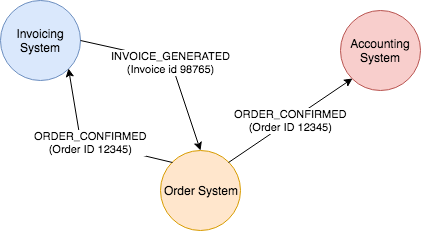
“Logs and Metrics” is a way of thinking which implicitly assumes the existence of two things – a stream of time stamped messages (in a file or whatever) which humans can read called “Logs” and a database (statsd, prometheus etc) of “named magnitudes” called Metrics. It then goes on to assume that the business of Observability is to correlate these two. Many people will add a third dimension of “traces” to this mix (no one did that in response to my article, which IMO indicates that distributed tracing is a lot less adopted than the blog-osphere indicates).
E.g. Logs will have something like :
Timestamp 1 : Calling service A with payload XXXX
Timestamp 2 : Received response from service A : YYYY
Metrics will have
svc-A-call-count : 1
svc-A-resp-time : ZZZZ ms
We can clearly see that the second piece of information is entirely derivable from the first, if only the first meant something. Logs as we see them today are not information, they are just data. So it takes a human to collate these two things and figure out what is going on. The need for metrics despite having logs actually points to the fact that we are doing something very wrong
The event logging paradigm is targeted at solving this problem. Events mean something – they are information that can be automatically processed into higher order information about system health.
E.g.
Event 1: {eventTime : 1234567, eventType: “request-sent”, target: “service A”, payload: “XXXX“, requestId : “E1”}
Event 2: {eventTime : 2345678, eventType: “response-sent”, target: “service A”, payload: “YYYY“, requestId : “E1”}
It is not hard to write an automatic mechanism for collating these two into a higher understanding which can be called a metric if we want. There is no reason for the events to be human readable (as it would be with logs) because machines can understand them and process them into the real thing that humans want to know – the system is working well (or not).
The fact is that some things happen in the real world system, and by “logging” them as arbitrary strings, we lose their semantics except to the trained human eye. We then try to cover this up by introducing more things like metrics into our system that again takes a human to understand. This is clearly a poor way to use technology.
Log meaningful events, and use event processing systems to derive information from them. Humans should be overseers, not operators of Observability.
Logging is about the implementation
A lot of people agreed with the idea, but objected to introducing yet another mechanism into their stack. They seemed to believe that they would require a message bus like Kafka for events while at the same time putting their “logs” in files.
This was a completely unexpected response for me, and it took some time for me to parse. Just to be clear, “Logging” or “Events” to me is not about the method of delivery (e.g. things sitting on a *.log file versus going over Kafka/RabbitMQ). The internal implementation does not matter as much as the mental model behind the act of logging. We don’t have to introduce another component – We can put events in files or logs in Kafka. It does not matter as long as we can distinguish between the two and use them appropriately.
I feel that this is yet another confusion stemming from the idea of logs as “messages to myself on call” being different from events (something informationally meaningful) and hence the urge to treat them differently.
Read Next – Data change stream are not domain events
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership


Indeed this is a fantastic topic Kislay…
” I object to putting ad-hoc strings in Elasticsearch or files as an observability mechanism. It is chaotic at best, and misleading on average. ”
Very true but most observability tools and platforms are promoting this for their benefits 🙂