Every programmer is familiar with logs – messages we put in our code to figure out where the code execution is and what is going on in the system. Logs are deemed to be one of the three pillars of observability, and are heavily used by developers to understand system behaviour in production environments.
While much has been said about structured logging instead of the typical message logging (e.g. “Calling service A with id B…” or “Error occurred while doing X : could not find Y”), I want to push the idea further to answer the question – what to log? I propose we should approach logging from the perspective of publishing events occurring between systems and subsystems. I propose that there are no such things as “logs”, there are just events that happen between two interacting components, and analyzing the events gives us the health of a distributed system.
The inevitable march to structured logging
Let’s consider the evolution of logging in most systems, especially if a company is evolving alongside into microservices or some other form of distributed architecture.
Developers start logging messages into log files, and referring to these log files at runtime to see what the system is doing. Debug info, errors, exceptions all reach these files. Initially the system may be running on very few servers so that developers are able to access each of these log files individually. Eventually though, one of two things happen. Either a monolith has to be run on lots of servers to keep up with scale requirements, or smaller components start to break away into independent systems and the state of the system starts to get distributed. Both of these situations over time demand that logs from all different servers be pulled into a single log aggregation system. So that we can search for them in one place and debug problems effectively. The ELK stack is a popular choice for such aggregation systems.
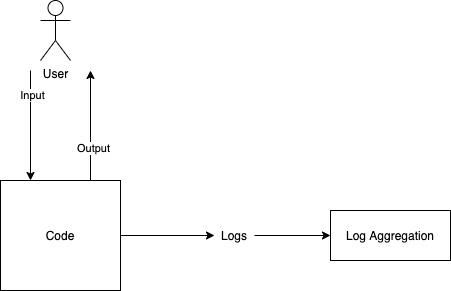
But other problems now start popping up. How do we tie together work that was done across multiple systems for a single user action. How do we track interactions done over asynchronous channels like Kafka? What if the software is running across two data centers – how do we identify what is happening where? The most common solution for all these things is to add more metadata to each log message (often via a standard logging library). So we now have datacenter id, correlation id,traces/spans and other such data points getting appended to the log message. Developers are still thinking in terms in terms of strings like this.
2020-09-23 17:08:13+0530 INFO [thread=main] [uId=user54672] [reqId=avsk4ghaioernkva] [cId=5] o.e.j.s.Server - Started @7217ms
2020-09-23 17:13:12+0530 INFO [tid=Timer-0] [uId=user54672] [reqId=avsk4ghaioernkva] [cId=5] c.c.g.t.LocationServiceTimerTask - Updating cities and countriesIn fact, the log message has effectively become this.
{
“thread” : “main”,
“uId” : “user54672”,
“reqId” : “avsk4ghaioernkva”,
“cId” : 5,
“class” : “c.c.g.t.LocationServiceTimerTask”,
“Message” : “Updating cities and countries”
}This march from unstructured logging to some sort of structured logging is inevitable in any company that survives long enough to tell the tale. I don’t get why we don’t just accept this and do logs this way from day one. Anyhow…
What are we looking for?
Let’s dial back a little bit and think about why we are logging things anyway. We usually log things to get visibility into the state of our running code. Typical interesting things
- Errors occurring
- State of the system when some error occurs
- Rate of successes/failures or various activities
- Operations happening on different entities.
This small set of sample requirements is so wide ranging that it makes many people say “log everything.” This is neither necessary nor feasible.
It is not necessary because most of the things happening inside a system are trivial and boring (think most logs). We could ignore them without any risk. So logging everything would only be cluttering the systems with log statements everywhere for no reason.
Logging everything is also not feasible because logging is not free of cost. The system suffers a performance penalty for every log emitted, the wallet of the CTO pays the penalty of storing the logs for search later, and the log aggregation system pays the scalability penalty if every system starts logging everything. It is not possible for the log management system to scale out to handle indiscriminate logging by all other systems.
In any case, “log everything” is not much of a guideline. What is “everything”? Every single line of code? Obviously not. Ideally we want to log what matters, but how do we know what matters? “Log everything” doesn’t help there, but system boundaries do.
Boundaries are the happening places
No system without some boundaries endures the real world. As part of the design process, developers divide the larger system into smaller logical or physical modules. The boundaries encapsulate the internal details of how things are done from other parts of the system. One way of looking at this is that from an observability perspective, most of the interesting activities in a system happen at its boundaries, while most of the boring things happen inside boundaries. The modules themselves might be very complicated, intricate pieces, but when observing the system, its health and state can be observed at its edges.
Boundaries are of many types. They may be REST APIs and message queues, they can be interfaces and abstract classes in the code, they can be the APIs of other libraries being used in a system. The question of why something is considered a boundary instead of something is tied inextricably with the opinions of the designers of the system, and changes dynamically as a system evolveds. So to observe a system effectively over time, not only do we need to identify the seams within it, we also need to be able to systemically keep up with the changes in them.
Where are the boundaries?
Let’s say we have an invoice service, which calculates the value of an order and saves it in a database. Let’s say the invoice generation code looks somewhat like this.
public class InvoiceService {
public Invoice generateInvoice(Order order) {
if (order.ItemCount() > 0) {
double amount = 0;
long amountCalcStartTime = new Date().getTime();
for (Item item : order.getItems()) {
amount += item.getValue();
int taxAmount = computeTax(); //Some complicated tax logic
Amount += taxAmount;
}
long amountCalcEndTime = new Date().getTime();
LOG.info("Amount calculation took {} ms", amountCalcEndTime - amountCalcStartTime);
order.setValue(amount);
Invoice invoice = convertToInvoice(order);
long dbWriteStartTime = new Date().getTime();
InvoiceDao dao = new InvoiceDao();
Invoice persistedInvoice = dao.saveInvoice(invoice);
long dbWriteEndTime = new Date().getTime();
LOG.info("Persisting invoice to DB took {} ms", dbWriteEndTime - dbWriteStartTime);
return persistedInvoice;
}
LOG.error("Persisting invoice to DB took {} ms", dbWriteEndTime - dbWriteStartTime);
throw new IllegalArgumentException("no items in this order");
}
}While this is not bad code, looking at it doesnt tell me what I should be logging. Even more importantly, how can I be sure that any logs I add now will seem important enough to future developers that they retain them through refactoring/code changes. In short, there are system boundaries that aren’t very obvious. For want of boundaries, we cannot tell what is important except by relying on tribal knowledge.
Let’s refactor this code into something like this.
public class InvoiceServiceNew {
public Invoice generateInvoice(Order order) {
AbstractAmountCalculator calculator = new ItemAndTaxBasedCalculator();
order.setAmount(calculator.calculate(order));
Invoice invoice = convertToInvoice(order);
long dbWriteStartTime = new Date().getTime();
InvoiceDao dao = new InvoiceDao();
Invoice persistedInvoice = dao.saveInvoice(invoice);
long dbWriteEndTime = new Date().getTime();
LOG.info("Persisting invoice to DB took {} ms", dbWriteEndTime - dbWriteStartTime);
return persistedInvoice;
}
}
public abstract class AbstractAmountCalculator {
public Double calculate(Order order) {
try {
long amountCalcStartTime = new Date().getTime();
Double amount = doCalculate(order);
long amountCalcEndTime = new Date().getTime();
LOG.info("Amount calculation took {} ms", amountCalcEndTime - amountCalcStartTime);
LOG.info("Invoice amount for order id {} is {}", order.getId() - amount);
return amount;
} catch (Exception e) {
Log.error(e.getMessage());
throw e;
}
}
protected abstract Double doCalculate(Order order);
}
public class ItemAndTaxBasedCalculator extends AbstractAmountCalculator {
@Override
protected Double doCalculate(Order order) {
if (order.ItemCount() > 0) {
for (Item item : order.getItems()) {
amount += item.getValue();
int taxAmount = computeTax(item); // Some complicated tax logic
LOG.info("Tax for item {} is {}", item.getId() - taxAmount);
amount+= taxAmount;
}
return amount;
}
throw new IllegalArgumentException("no items in this order");
}
}Now there is a very clear boundary between the service and the calculator. Not only is this boundary likely to endure over time since it is more formalized, it is also hardened to take care of logging what happens at the boundary. The logging is also likely to endure better because it is baked into the scaffolding of the system. We can do further refactoring of a similar type with tax calculations and with the database persistence layer
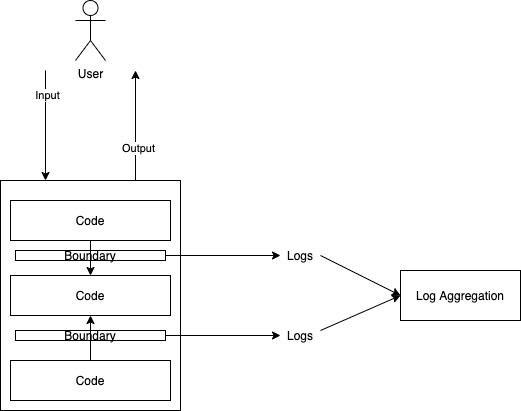
While this is a simplified example, the principle of defining boundaries and logging interactions cross them is a valuable one. Embedding the logging within the seams of the system is even better since that way it will not go away unless the boundary itself changes. In this way we can use “what to log” and “where to log” as nudges towards good design rather than ambiguous directives to log “the important things”.
Structured logs are just half assed event
Whether we think of them that way or not, log messages are events that have been poorly thought through.
If we look at our system now, we can see structured logs with metadata being emitted from system boundaries. This is literally the definition of domain events! Domain events are emitted from a system domain when something of potential note to the outside world happens inside the domain. That is exactly what we are doing here. So we should wholeheartedly acknowledge the idea that there are no “logs” – there are just events which define what happened inside a boundary alongside all relevant metadata. Here’s a sample of our world view in this new age.
{
“eventName” : “INVOICE_AMOUNT_CALACULATION”
“Type” : SUCCESS,
“eventTime” : 12344847339485,
“Metadata” : {
“thread” : “main”,
“uId” : “user54672”,
“reqId” : “avsk4ghaioernkva”,
“cId” : 5,
“class” : “c.c.g.t.ItemAndTaxBasedCalculator”,
“Message” : “Invoice amount is 1000”
“OrdeId” : 1,
“InvoiceAmount” : 1000
}
}This paradigm shift matters because treating logs as events makes them first class citizens in the design of the system. We are no longer logging requests, responses, errors, stacktraces etc willy-nilly – we have a formal vocabulary for defining what is important in our system, and we are logging all events at the intersections of our technical domains. Not only this, now logging can be a means of informing our system design. If there are some things that we feel like we should be logging, but we cannot find a boundary along which this logging should happen, or we cannot structure the log cleanly, we may be looking at a poorly defined or missing system interface.
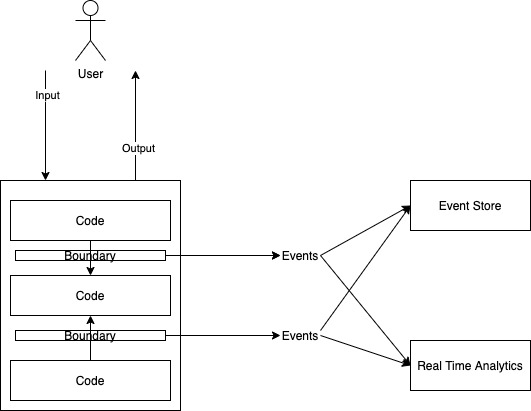
Single mode of observability
If events represent all interesting activity happening at the system’s boundaries, then we ought to be able to observe the important bits of our system’s runtime state through them. And if this is true, it follows logically that we don’t need multi-modes of observability. Metric, traces, etc are all derived attributes of the combined event stream of the system, and what we actually need is a powerful means of querying these event streams/stores. Standard database systems, stream processing systems, complex event processing can all be leveraged on this single source of truth to generate a rich variety of insight into the live system. This reduces the need to maintain multiple sources of truth for the same information – as we do when we treat logs, metrics, and traces separate from each other. System events right with business metadata can serve the same purpose very effectively.
I hope I have conveyed why I believe that logging as understood commonly is an ad hoc activity, and cannot handle the unknown-unknowns of a production system. We need to switch to an event perspective to leverage it more effectively for system design and reliability.
Read next : More articles about distributed systems.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership




I don’t think its that binary. Events at the boundaries are great to inform data when you know what could potentially go wrong. Imagine this line of code:
int taxAmount = computeTax(item);
Now this method is supposedly doing the right thing but maybe doing something very naive like casting a double to int and truncating its value as it returns it. It would be hard to spot this via boundary events. You have to debug the computeTax method using the logs, see what the inputs are, see what the computation is, and do it on a piece of paper to verify that it is doing the right thing in all cases. That requires turning on detailed logging at this app/method/namespace level. But if the developer doesn’t have good logging, whether its an event or writing to a file, then it’s tough as nails to spot such subtle bugs.
So while using events instead of writing to files and later using aggregation is definitely an improvement to logging, limiting to good logging events primarily at boundaries may be tad simplistic IMHO.
This might be of interest…
https://medium.com/@autoletics/redesigning-observability-logging-70153f9f06d9