In the last two posts in this series, we looked at the various asynchronous programming paradigms to reduce thread blocking, and then took a deep dive into asynchronous programming done via thread pools. Now let us look at the true non-blocking style of coding, and how we can use IO-interrupts as events to build systems that hold up in the face of massive load.
As before, let me repeat that whenever I say “blocked thread” in this discussion, I mean threads blocked/waiting on IO. We should also remember that we are not talking about event-based communication between two systems. We are talking about using IO-interrupts (IO started, IO completed etc) as events to control the behaviour of threads within a system.
What is event-based programming
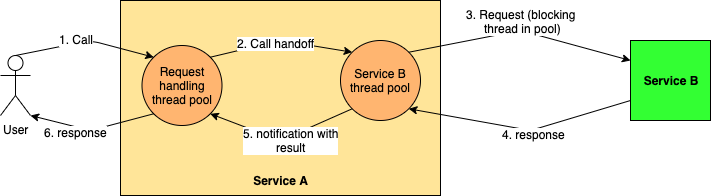
Event based programming approach relies on having no blocking code in our application. This means that a thread initiates an IO operation (e.g. a thread in service A calling service B’s REST API), and then switches over to doing other things. When the IO operation completes, this thread is notified (interrupted) to come back and handle the result of its operation (deserializing the response). From the perspective of calling thread, the whole IO stage becomes outsourced to someone else, who will notify it when the job is done. The thread then starts executing the code path from where it left off before.
From 30000 feet, this description looks very similar to our discussion of asynchronous programming via thread pools. But there is one vital difference. While thread pools were being used to isolate blocking IO from the calling thread, here there is NO blocking code whatsoever. We don’t need a thread pool on the other side of the calling thread accepting the request and notifying the calling thread back. However, that leaves the question of who issues the interrupt on completion of the IO operation.
The answer is — the operating system. *nix systems and their derivatives have long had the support for accepting a IO hook from an application, keeping track of the IO lifecycle, and notifying the application when IO is complete. By leveraging this, an application can eliminate IO management from its concerns and simply focus on triggering IO and handling the result.
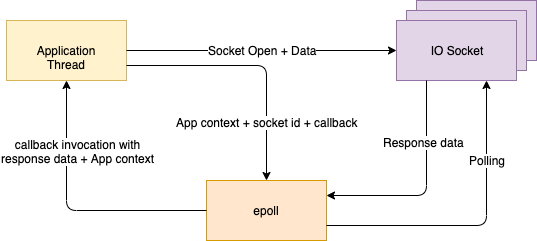
Handling task handover
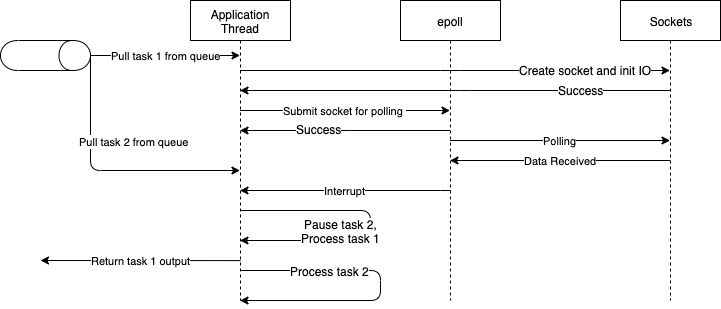
The way IO happens is that the application opens a socket and then issues commands to start sending and receiving data over that socket. Once the request data is sent, a typical application using one-thread-per-request model would just sit and poll the socket to see when the result is received. This is the origin of blocking IO.
Non-blocking, event-based applications, however, handover this waiting stage to the OS. The OS comes with a polling program (epoll/selector/others depending on the distribution) which can handle polling of sockets for data very efficiently. The application adds its own socket to the list of sockets being polled and gives it a hook (aka a callback) that epoll can use to inform the application when the socket receives the response and the inbound data stream is ready for processing. The application thread is now free to process other tasks.
ALL application threads are now free to process non-IO tasks (because there is no blocking IO whatsoever) giving the application the ability to handle massive scale.
Handling task completion
Epoll will keep polling all of the sockets registered with it, typically using a single thread. Once a socket receives data, epoll invokes the callback given to it by the application with the received data and the thread execution context (also stashed here by the application when handing over to epoll). Of course, epoll doesn’t understand what the data is, just that there are some bytes that the application can process. This callback interrupts an application thread to handle the output (deserialize, run business logic etc).
Note that in this event-based style, the task handover and thread interrupt are happening across the Application-OS boundary. This exchange is often called the event-loop. Node.js made event-loops famous by being one of the first application development frameworks to leverage NIO to build single-threaded(!!!) applications that could nonetheless serve a massive volume of traffic so long as the lion’s share of work was IO-bound. These days, there are frameworks in most languages that will do this (Vert.x is a great example).
Elegance and Scalability
I love the event-based style because it is so much more elegant from the perspective of application design than the work-stealing style. The application does not have to tinker around wrapping blocking calls in thread pools or deal with sensitive application behaviours resulting from thread pool sizing. The entire application can behave asynchronously without having to deal with the specifics of IO management — we just initiate IO, don’t stick around, and come back to handle the output when it is ready. Scalability in style!
Coding Time!
Let’s revisit the code for making an HTTP API call in the one-thread-per-request model.
public class Client {
public Response get(String url, Request request) {
// API calling logic
}
}public class CallingClass {
private Client client = new Client(); public void call() {
String url = “some-api-url”;
Request requestData = new RequestData();
Response response = client.get(url, requestData);
LOG.info(“Got data {}”, response);
}
}The thread running CallingClass code will block on the client.get() till it returns the data.The code in the NIO style looks very similar to the work-stealing style, except that there isn’t any task queue or worker pool of threads.
public class AsyncClient {
public Future<Response> get(String url, Request request) {
// API calling logic
}
}public class CallingClass {
private AsyncClient client = new AsyncClient(); public void call() {
String url = “some-api-url”;
Request requestData = new RequestData(); Future<Response> responseFuture = client.get(url, requestData); responseFuture.onComplete() {
// callback handler for successful future completion
LOG.info(“Success with data {}”, response);
}.onFailure() {
// callback handler for failed future completion
LOG.error(“API call failed with response {}”, response);
}
LOG.info(“Moving on immediately”);
}
}This code will log “Moving on immediately” after handing over the IO control to the OS. epoll will interrupt the thread running CallingClass on receiving the API response. The application then parses the data to understand whether we have a success or a failure and then invokes the corresponding handler bound to the Future.
Note how this code is far simpler than the code of the work stealing style, even though it suffers from the same callback-hell problem.
Limitations to scale
Awesome as the event based programming paradigm is, there are limits to what we can achieve with it. The limits to scalability in this model come from the following factors.
Memory Overhead
Every time a thread hands over to the OS an IO task, it also hands over the data in its execution stack for safe-keeping (so that it can resume from the same point on receiving completion interrupt). This info is kept in the memory and as more and more threads stash away their data, we can start running out of memory. This only happens at a very high scale, but then again, we don’t do this style of programming for a low scale.
Data Copy Overhead
When we use NIO, data and control switch between the operating system’s user-space (where application code runs) and its kernel space (where epoll runs). The data copy from user space to kernel space, and then back to user space can be very expensive at the OS level. Light-weight threads avoid this problem by keeping all their data in the user space throughout, and worker thread pools don’t have this problem because they never hand over control to the OS.
Blocking code in other parts of the application
I once read somewhere that “the best way to do something in node.js is to do nothing in node.js”. This statement says a lot about what non-IO operations can do to the scalability of an application. While our IO is non-blocking, all the rest of the application is still blocking, starting from serializing and deserializing IO data. As a result, the overall throughput of the application is now defined by and limited by how much CPU bound work it has to do.
Too many interrupts
A single application thread can potentially handle thousands of requests. However, what a single thread cannot handle is a flood of interrupts resulting from the simultaneous completion of those requests. We may end up in a situation where the application thread gets interrupted so often that it cannot serve any request completely without adding a lot of latency.
Maximizing CPU usage
It is true that a single application thread can suffice, using NIO, to serve way more traffic than traditional applications. However, server hardware typically has more than one CPU core and if we run just one application thread, we are leaving a lot of hardware capacity on the table. Single-threaded applications are also more susceptible to the last two problems mentioned above (performance degradation due to blocking code and too many interrupts).
The multi-reactor pattern offers a way out by running more than one event loop thread (twice as many threads as there are CPU cores is often recommended as a rule of thumb). This adds a lot of capacity to the system by making full use of all the cores so that blocking code and the number of interrupts are less of a problem.
Not everything can be non-blocking
The event-based programming paradigm is premised on having APIs which do not block a thread for IO operations to complete. Typically these places are network calls to remote APIs, DB queries, File read/write, etc. In practice, it is rarely possible to make ALL our code non-blocking. Databases, especially RDBMS, usually have poor support for NIO (primarily because of the way transaction support is implemented). Application containers too, need to support asynchronous programs. If my REST service returns a Future<Response>, the application server (e.g. Tomcat) should be able to understand this and have corresponding event-driven code of its own to handle the client requests. This, unfortunately, isn’t widely adopted.
As a result, we cannot always have a system built entirely on events. To work around this, we often see a combination of NIO (where the APIs allow), thread pools (to convert blocking code into async mode), and plain old blocking code in most applications
Did we really change anything?
You would have noticed that epoll still has to run a thread to poll all the sockets which is essentially a blocking operation. So aren’t still, in a sense, using thread pools (a thread pool with only one thread)?
This is correct, but for the fact that we (i.e., the application) are not doing this anymore. The application is completely event-driven, and the OS is extremely efficient at handling low-level operations like socket polling. Of course, this puts a limit on how many operations we can do (like the data copying concerns highlighted earlier) but overall the event-based style results in applications that are vastly more scalable than one-thread-per-request applications and much better designed than thread pool style applications.
Read Next : More articles on asynchronous programming
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership