Let’s say there’s a method in the codebase that does 4-5 things one after the other. The code for doing all those things is well-written, but the result is a somewhat large method. At what point should you break it up into multiple methods? There is the old adage about every method being fully visible without scrolling which I have always found weird. Let’s try to do better.
The good part about having all of the code inside a single method is that it is all in one place and in a sense, easy to absorb in one shot. The bad is part is that it makes the method large and if split, the reader will have to move in and out of multiple methods to understand what is going on.
I prefer the second approach because smaller methods are easier to understand for me. But there has to be a balance in that direction too. So while the correct answer is obviously “it depends”, I’ll try to give a little more in the way of guiding principles.
The key to writing or refactoring software is to reduce the cognitive load on the reader/maintainer of the code. All other considerations are subservient to that goal (of course, “it depends”). So the key to answering the question of granularity is to identify how people read and understand any piece of code. Or rather, how do we want them to read a piece of code.
Typically people read code from a higher level of abstraction to a lower level of abstraction. The guiding principle of each layer of code, typically represented by methods, is that it should prevent the user from wanting to dig deeper into the next layer. Not in the sense of sending them away screaming as quickly as possible, but rather by making what must be happening underneath so obvious that the reader never feels the need to read the next layer. In the context of this article, cognitive load can manifest in two forms: engagement and curiosity. We don’t want them to feel like they have to think (engagement) to understand something, and we don’t want them to want to think (curiosity) about something. This is sometimes called the “Principle of least astonishment” and applying this can help us bound the upper and lower granularity of a method.
At each level, a well-written method represents a declarative (what is to be done) unit to work to its higher layers (the ones who called it) and internally contains a set of imperatively defined steps (how is this to be done). In this sense, our method in question which does 4-5 things, is in some sense a workflow. As I wrote in my previous article on workflows, the place where a workflow is defined should only define what steps are to be taken, not how each of them works internally.
Let’s take the example of booking a doctor’s appointment at a hospital. A makeAppointment(hospitalId, doctorId, patientId, startTime, endTime) method can do several things:
- Check the working hours of the hospital
- Check if the doctor has no other appointment during that time
- Book the appointment
- notify the doctor of the appointment
- notify the patient of the appointment
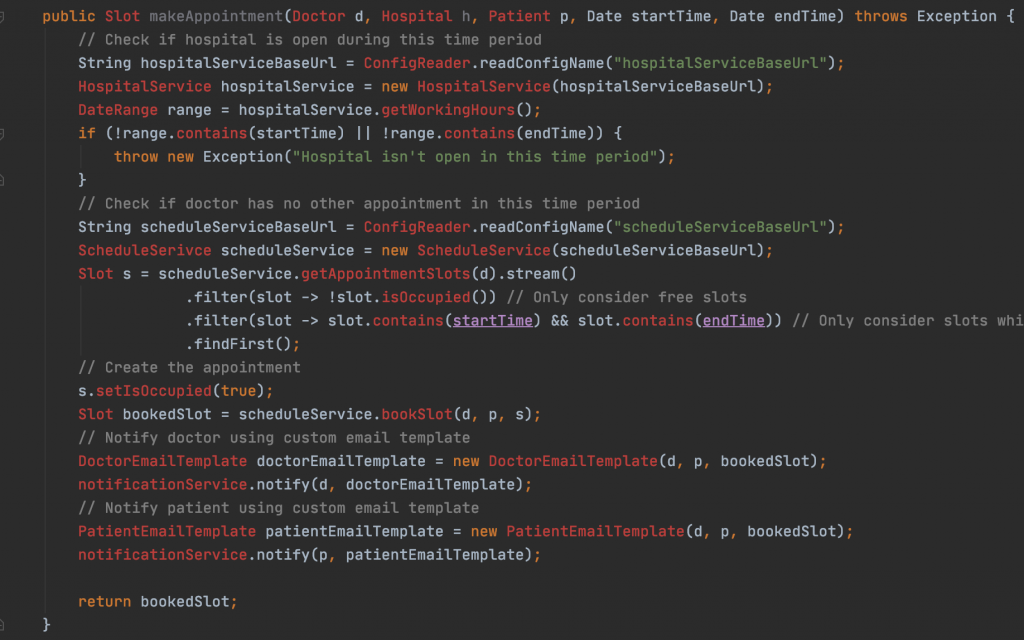
Let implement this by putting all the code in one place (gist).
This method is not so bad as some real-world code you may have seen. But the moment I reach this method, my brain has to wake up to the details of everything going on here. I wanted to understand how an appointment is booked but suddenly I’ve run into a bunch of API calls and other things. This doesn’t exactly match my mental model of how to book an appointment. This result is a high cognitive load. Therefore, this method should be broken down till it reaches the mental model “in English” as much as possible. Here’s a possibility (gist).
This looks a lot more like the workflow I was expecting. The details of each of the steps are now hidden, which means that they can change without us knowing about that. But the biggest thing is that I don’t feel like I have to go into each of the new methods to see what they do if all I want is a logical understanding of how appointments are booked. There are technical things like exceptions that still intrude upon the reading experience, but for the most part, astonishment has been eliminated by reducing the model-code gap.
Now let’s go one step deeper and further break down the methods here (gist).
Note the buildScheduleService method. If I really want to understand how ScheduleService is invoked to get a doctor’s schedule, this still looks all right, although just about at this stage someone will start arguing that service creation should not be done in this class or that it can be more generically for all service. That’s fine, it can still stand alone as a method, if not in this class then elsewhere. But the question indicates the curiousity/astonishment quotient has started rising.
Let’s take it one step further (gist).
Any developer with any amount of experience in any codebase will get curious as to why we need a separate method just to throw an exception. They will try to go to the lower level to understand it, which is exactly what we set out to prevent. At this level of granularity, our method size is causing astonishment so we should abort this step.
The point at which engagement or curiousity begins to rise depends on the business and technical context of a codebase. So while this is obviously a simple example, preventing cognitive load is widely applicable as a guiding principle in software engineering. When reading a piece of code, keep in mind your engagement and curiousity levels. If either increase, there may be the possibility of refactoring.
Read Next: Code review checklist for distributed systems
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership