What is the most popular style of arranging code you have come across in enterprise codebases? The one I have seen most often groups all classes (assuming Java-land) by the layer in the tech stack. So in an MVC style system, all controllers are together, all services are together, all repositories are together, all POJOs are together etc. Let’s call this convention the “stack” style of organizing code.
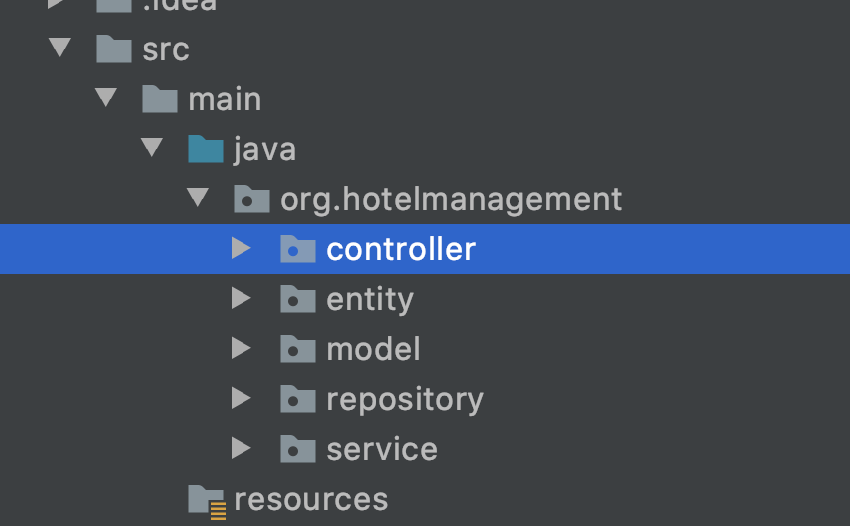
This is a terrible way of organizing code and I will explain why below. But first, allow me to offer the alternative.
A much better way of organizing code to group it by the logical entities it represents. Let’s call this the “entity” style of organizing code. The idea is to make sure that all classes related to a single concept stay together. By putting the logical entities first, we are optimizing for human comprehension (compilers don’t care where you put which class). By virtue of how the code presents itself, developers are nudged to make smarter choices about where the actual system boundaries lie. Not between SomethingRepository and SomethingElseRepository, but between Something and SomethingElse as concepts.
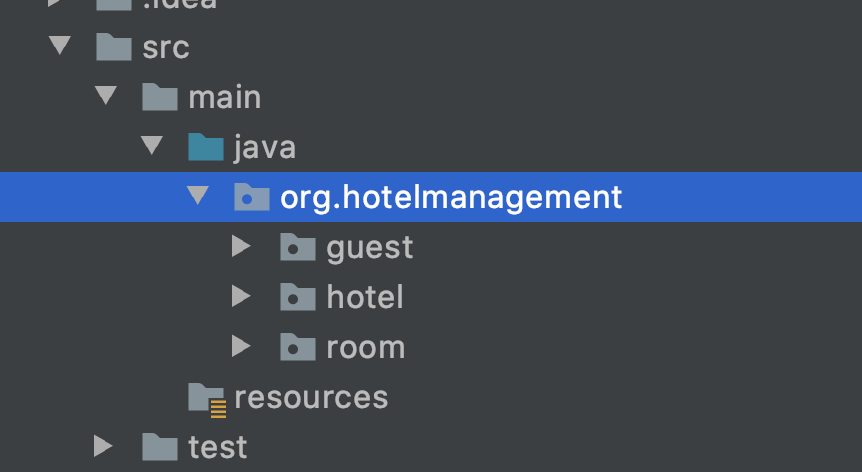
Now let’s understand why I think the entity model is better than the stack model.
Improper abstraction
People don’t read code by layers of the stack. No one ever says “show me all the APIs of this system” or “give me all the queries being fired by this system”. People read code along domain boundaries. In a hotel management system, people think about rooms, and guests, and prices, and so on.
Since “stack” style code is organized along technology layers, it is difficult to understand the logical model of the system from the way it lives in the repository. The boundaries the “stack” style exposes are technical layers. We cannot understand the “nouns” and the relationships between them from this code. You have to dig one level deeper for that. For a new person reading the code, this obfuscation of “logical” structure is a huge source of friction.
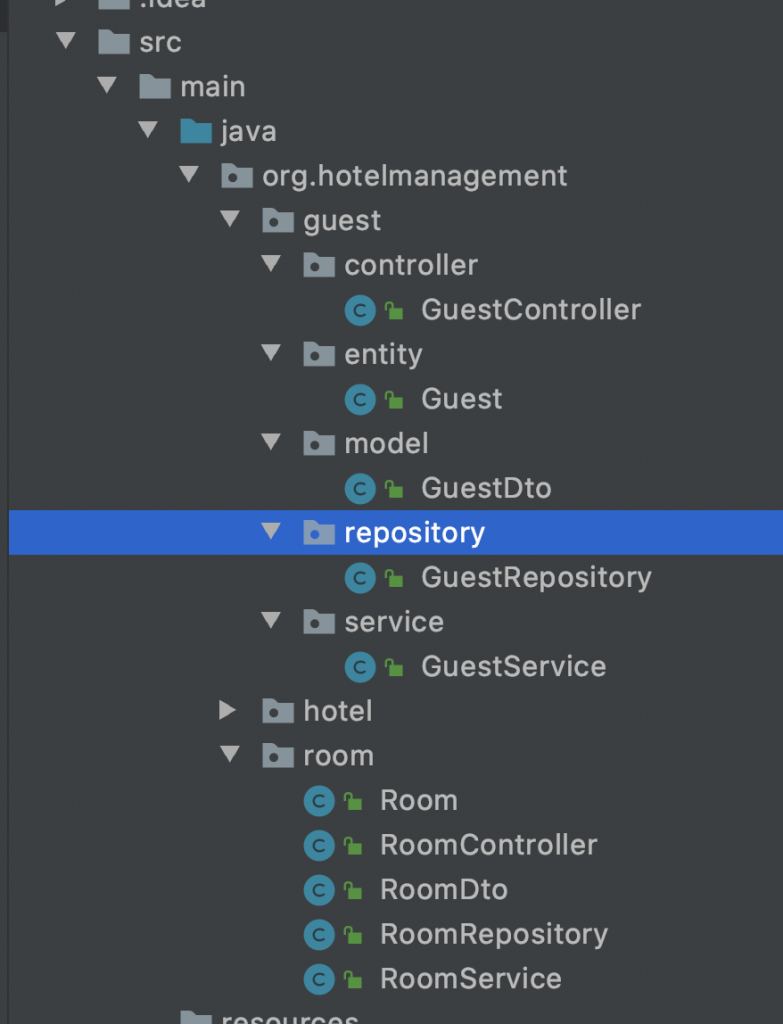
In our hotel management example, the “entity style puts all code related to guests (regardless of the technical layer) into one package, all code related to rooms goes into another, and so on. Each of these packages can have its own internal organization in the “stack” style or just a few classes all at the same level. This makes it easy to find everything related to guest in one place.
Poor cohesion
Another common argument given for the “stack” style of arrangement is that it puts separate modules at different layers of the tech stack. e.g. Controllers are visibly separated from service, service from repositories etc. To find classes at different levels of the tech stack, you need to go to packages representing those levels. This encourages decoupling between the different layers.
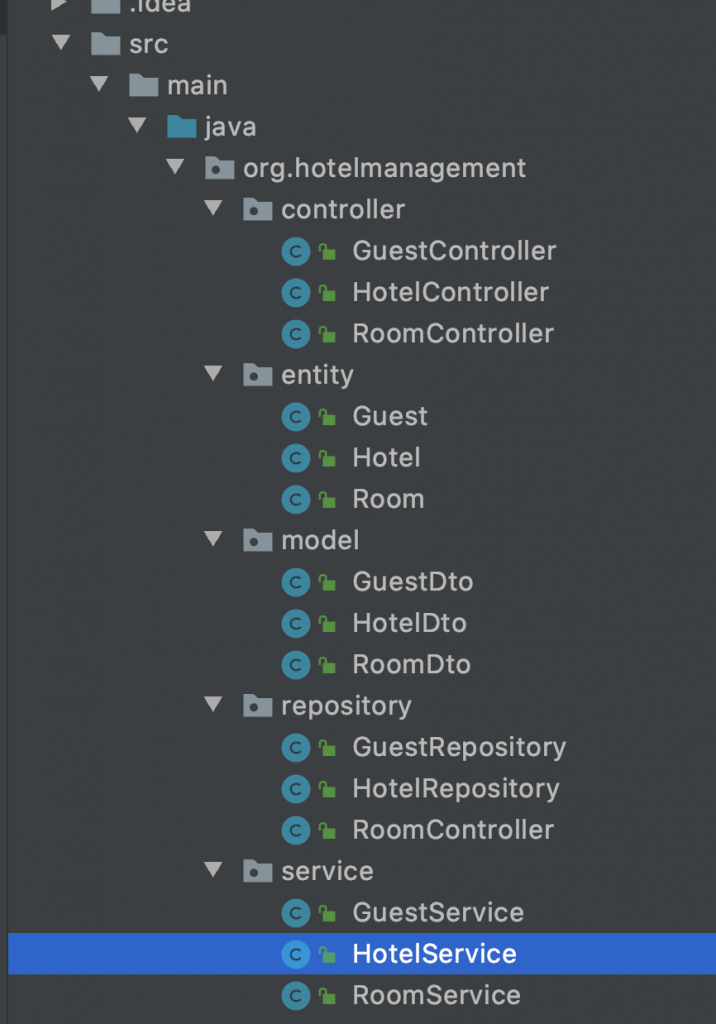
The problem with this argument is that it focuses on coupling but disregards the other critical property – cohesion. Between what classes do we want to increase cohesion and which do we want to decrease coupling? Since all services are located together, can we say it is okay for them to be highly cohesive but decoupled from their model classes or repositories? Can we allow all repositories to become highly reliant on each other but decoupled from the business logic of the service layer? The obvious answer is NO! This kind of code would be textbook big-ball-of-mud. Refactoring such a system into smaller systems would be an absolute nightmare because you would have to decouple classes at every layer of the tech stack. It defeats the whole purpose of using an MVC style.
The “entity” style, OTOH, promotes cohesion while still leaving room for tech stack style decoupling. It is okay if all hotel-related classes depend on each other (technically or conceptually) since they form a single unit of work anyway. It also makes future refactoring easier because the logical boundaries are clearer than in the “stack” style.
Hard to change
To make any meaningful change in a codebase organized in “stack” style, a developer has to cut across multiple packages. e.g. to add a new field to an entity and its CRUD API, all packages will be modified. This creates cognitive load because the developer has to modify many “things” rather than a single logical thing.
In the “entity”, if you change a thing, you make changes only in one logical boundary. This makes changes to them easier because we are working only in a small part of the codebase if working with a single entity. If you cut across top-level packages, you are cutting across logical constructs by definition and this will alert you to potential coupling-related considerations.
Limits design choices
Since code is organized by tech stack or functionality, it limits the way people think about system design. e.g. Since business logic should go into “services”, developers resist using proper design constructs and would rather shove everything inside services thereby creating nightmare classes thousands of lines long. Even when they use good design principles, the organization of the code resists them because every new “type” has to be in a unique package. If I want to use the factory pattern in different services, then I have to invent a whole new package hierarchy called factory and henceforth all factories should go there whether or not they have anything to do with each other.
As I mentioned earlier, the “entity” makes no assumptions about how each logical package is grouped internally. It can be in the stack style, or have as many types of packages as required without influencing the choices made in another entity’s package.
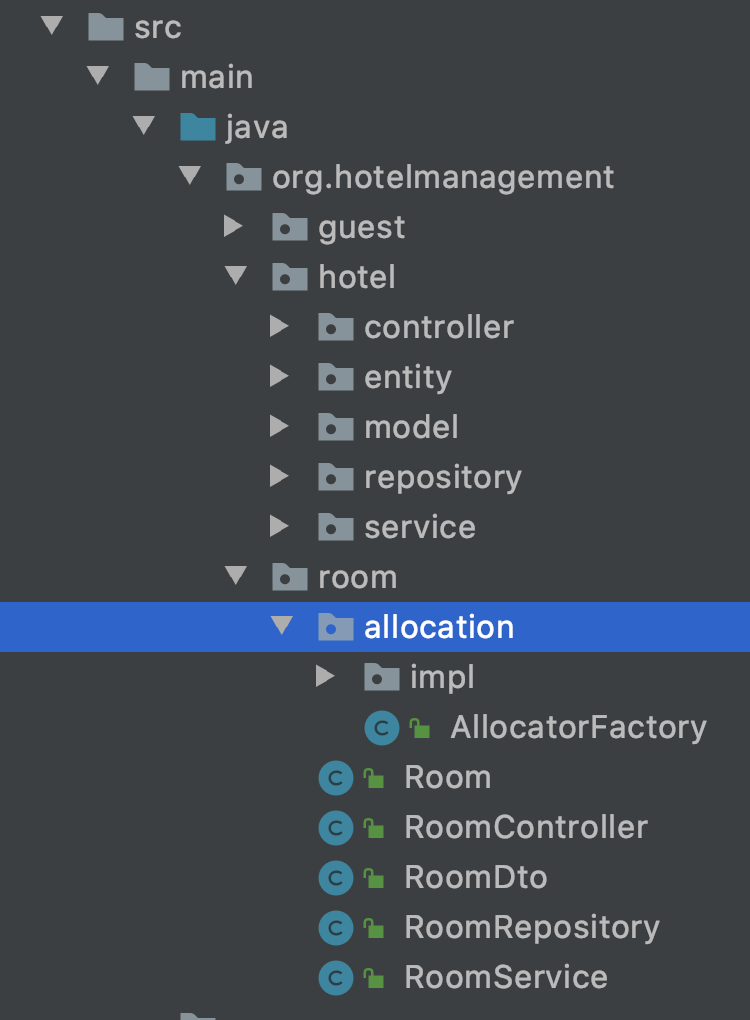
One concern here can be about how to organize things that span across entities. e.g. workflows operating on multiple entities. Neither style has a neat answer to this, but IMO the “entity” style does a better job at it since it forces the creation of a new package outside all entity packages. This highlights that a workflow is a new concept and potentially a system boundary that should be developed independently. The idea is to group similar concepts together, but things not bound to a single concept can still have their own logical homes in the base.
The modes of thinking that code organization promotes is something I feel we don’t think about enough. This is similar to Conway’s law at codebase level. I’d love to hear more from you about how you organize your code sand how you think it shapes developer behaviour, mental models, or efficiency. Drop a note in the comments!
Read Next: Unit testing is a tool for designing, not merely testing
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership



very useful. Can I translate into Chinese? I will put the original url in
Sure lukeaxu. Please let me know where you are going to post the translation and link it back here!
Thank you very much. Translation(Chinese) there: https://www.testwo.com/article/1622 and the source link in can back here
Good one!