For the first nearly ten years of my programming career, I hardly wrote any unit tests. I wrote a lot of code, and tested almost all of it by running it and testing for end-to-end behaviour, mostly manually. However , as I started inheriting larger and larger codebases and projects across multiple teams in my role as an architect, I began to see why everyone went on about unit testing. There usually isn’t a faster way to know that the code you are writing is safe and works as expected. This is a huge safety net during refactoring complicated code. It is certainly cheaper than having to start a service with its datastore and other attending paraphernalia just to see if a small change is fine. Good unit test coverage also serves as a good and fast way of ensuring that you are shipping the right thing in the land of CI-CD etc. Running integration tests which require elaborate set-up if you want to deploy very often can be very expensive on the infra.
However, after writing unit tests regularly for a few years now, I have realized that there is a much deeper value in them. Unit tests (with mocking etc) don’t just test code, they make sure that the code is testable in the first place. The act of writing tests helps improve the design of the code during the process of writing. Ever since I realized this, I have become a lot more rigorous in writing tests – not because I care a lot for the testing itself, but because writing them makes my code better designed, more modular, and reveals hidden boundaries in it.
To test is to draw boundaries
Let’s consider what we are doing when we write tests. We provide some input to a piece of code (bunch of classes, class, method), and we verify that the output is what we expected it to be. This idea of input and output implicitly defines boundaries – a boundary from outside which we feed in the input, and a boundary outside which we receive and inspect the output. There may be many code paths inside this boundary, and we want to exercise all the paths in our testing.
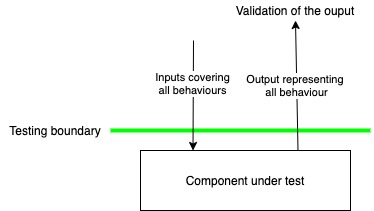
The definition of expected output depends on the boundary we choose. A REST style create API can be tested in several ways. If we choose to include the database inside the boundary, the expected output is an entry in the database (for a valid input). If we draw the boundary just before the persistence layer, expected output may be a valid entity for insertion or a lack of exception or something like that. So the tests are necessarily impacted by the choice of boundary. And good testing strategies exploit this to discover/create boundaries in the code and make them more concrete. This improves cohesion in the code (we identify things which can be collectively hidden behind a boundary) and decreases coupling (we separate things that should not get bundled behind a boundary)
But boundaries are often hidden
public boolean isUserActive(String userId) {
RestClientForUserService client = new RestClientForUserService();
User user = client.get(userId);
Return user.getIsActive();
}To test the above code, I would consider the method boundary as the boundary for both input and output and hence we should be able to test the behaviour of the method for both active and inactive users. However, doing this is difficult, because embedded inside the method is another boundary, i.e. the interface with user service.
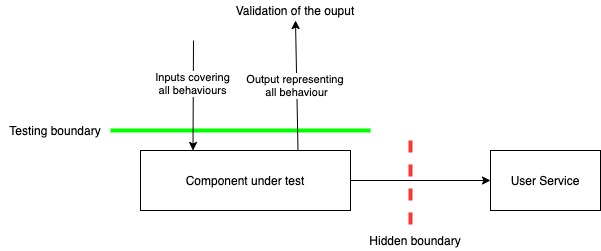
So to be able to write a test for this method, we need to be able to control what User service does. This can be done by actually setting up the user service to run this test. But this creates a hard dependency for testing – not a good idea. So we need to make this interface with user service externally accessible so that we can create the different conditions required to test all aspects of this method. We can do this by passing the client as an argument – this makes the hidden boundary more clear.
Public boolean isUserActive(RestClientForUserService client, String userId) {
User user = client.get(userId);
return user.getIsActive();
}Now we can mock this client in a test to simulate behaviour of user service. This is, in a sense, dependency injection, and can be done at class level.
This way of making explicit the dependency actually shows us one more thing – this method doesn’t need to know about User Service per se. What it needs is a source of User objects. So we can further decouple it from user service by introducing an interface and a service backed implementation for it.
public interface IUserDataLoader {
User getUser(userId);
}
public class UserServiceClient implements IUserDataLoader {
public User getUser(userId) {
RestClientForUserService client = new RestClientForUserService();
return client.get(userId);
}
}
public boolean isUserActive(IUserDataLoader userInterface, String userId) {
User user = userInterface.get(userId);
return user.getIsActive();
}This whole redesign has emerged just by trying to write a unit test. The boundaries of our code are much more clear, and we see a strong separation of concerns. This level of refactoring may be useful in some scenarios and overkill in others, but what counts is the thought process behind the thing. Testing makes the process of decoupling much more explicit at the time of writing the code.
I spoke about dependency injection earlier. Here’s a typical example from Spring land.
@Component
public class MyClass {
@Autowired
RestClientForUserService client;
public boolean isUserActive(String userId) {
RestClientForUserService client = new RestClientForUserService();
User user = client.get(userId);
return user.getIsActive();
}
}I used to love this way of injecting dependencies – no pesky constructors or getter/setter boilerplate. But as I started testing this, I kept getting stuck because the boundary represented by the User service client was not accessible. I don’t like the idea of setting up entire application contexts in tests – I prefer a little less magic and simple tests run faster too. So over time I have come to like the constructor injection method. While writing tests, I now have control over all dependencies (which essentially represent boundaries) and I can manipulate them (via mocking or dummy implementations) to test all behaviour of MyClass.
@Component
public class MyClass {
RestClientForUserService client;
@Autowired
public MyClass(RestClientForUserService client) {
this.client = client;
}
public boolean isUserActive(String userId) {
User user = client.get(userId);
return user.getIsActive();
}
}Let’s take a slightly larger example composed of multiple steps.
Public class Account {
String userId;
Date createdDate;
Date balance;
}
// Return true if account created, false otherwise
Public boolean createUserAccount(Account account) {
RestClientForUserService client = new RestClientForUserService();
User user = client.get(userId);
If (user == null || !user.isActive()) {
return false;
}
AccountDao dao = new AccountDao();
try {
dao.create(account);
} catch (Exception e) {
log.error(“Failed creating account”, e);
return false;
}
return true;
}If we want to test this method properly, we need to control every place where code branches off. In this example, branching is occurring at the user object and when trying to write the users to the database (UserDao is the class that inserts the object to the database, in JPA world this would be UserRepository). Let’s try a different approach than dependency injection here by splitting the original method into multiple methods and then hook into each of them via mocking.
Public class Account {
String userId;
Date createdDate;
Date balance;
}
// Return true if account created, false otherwise
Public boolean createUserAccount(Account account) {
User user = getUser(userId);
If (user == null || !user.isActive()) {
return false;
}
try {
persistAccount(account);
} catch (Exception e) {
log.error(“Failed creating account”, e);
return false;
}
return true;
}
@VisibleForTesting
protected User getUser(String userId) {
RestClientForUserService client = new RestClientForUserService();
return client.get(userId);
}
@VisiblForTesting
protected void persistAccount(Account account) {
AccountDao dao = new AccountDao();
dao.create(account);
}This code can now be tested by mocking the two new methods – something like this.
Mockito.doReturn(new User(active = false)).when(classUnderTest).getUser(Mockito.any());If we want, we can still use dependency injection to decouple the new protected methods from RestClientForUserService and UserDao even further. The @VisibleForTesting indicates that the method has been made protected or public so that it can be tested and should not be used by mainline code. It is, however, purely indicative. This is why I am not as big a fan of this approach as compared to the simpler DI based approach – it sometimes forces us to expose methods which would otherwise have been private.
In both these cases, our attempts at testing a method have done something awesome. They have turned the method from imperative to declarative. In both cases, the updated code simply states what is to be done while delegating the “how” to other components. It is much more decoupled that the original version.
Seams of Code
In his wonderful book “Working Effectively with Legacy Code“, Michael Feathers introduced us to the notion of “seams in code”. These are the places in our code where two components interact and thus where testing should be done. What we have done so far in this article is create these seams so that components can be identified and there are clear hooks to test the interactions between. But as I have written before, this idea can be pushed further to say that seams are the places where software grows and evolves.
If we have clearly drawn lines in the codebases where we can, through tests and other automated means verify the behaviour of both sides, it means that places offer the ideal starting point for software evolution. Both sides of a seam in the code can evolve in a decoupled manner so long as the across-the-seam contract is honoured. This makes the small refactoring we have done above much more powerful than it might seem at first glance. It is not just about testing or mocking or clean code – it is about laying the groundwork for all future evolution of the codebase.
This is why I now write unit tests – to make the design of my code better.
Read Next – Overcoming IO overhead in microservices
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership


Very clearly written. Good article.