The term “Seams” was introduced in popular language by Michael Feathers in his excellent book Working Effectively with Legacy Code as a place where we can alter behaviour in a program without editing in that place. Alternatively, a seam is a place in the structure of an application where two components meet, and hence a place where the interaction between them can be tested.
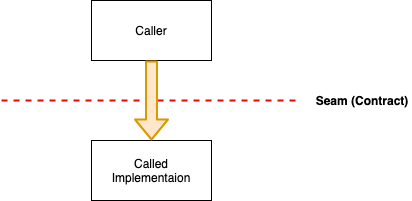
The term seam comes from the tailoring world as a reference to a place where two pieces of cloth meet and are stitched together. Since a seam is where two components of the application interact under well-defined rules, it makes a great place for testing since we can replace one component with something else (mock) without impacting the behaviour of the other. Intercepting the workflows across the seam makes for excellent integration testing.
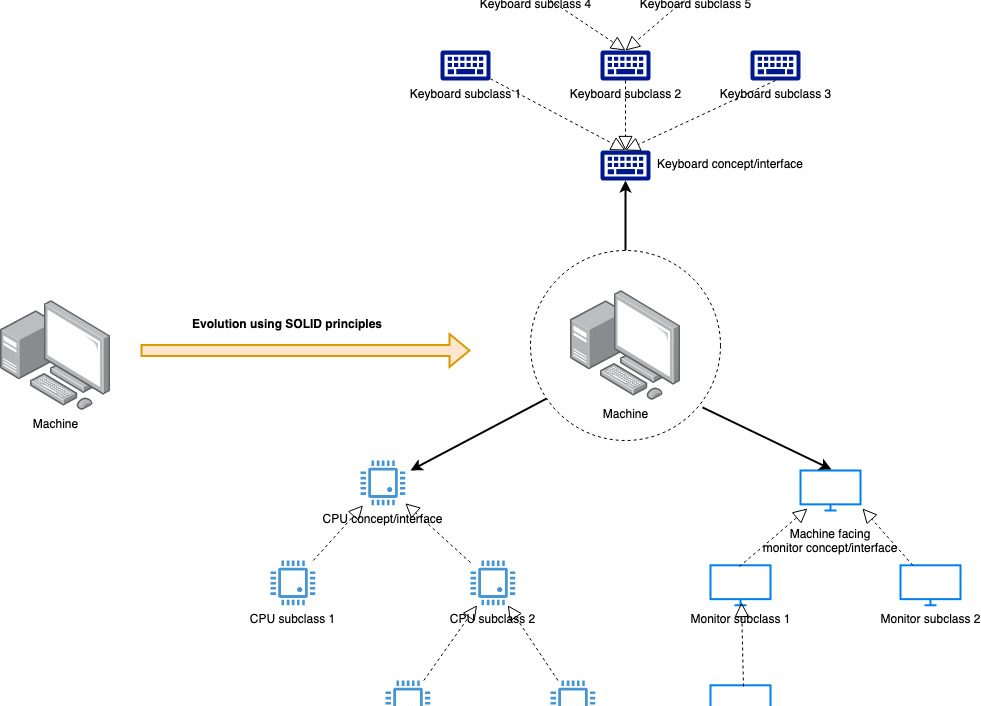
From a software development perspective, this is an elaborate way of saying “code to interfaces, not implementations”. However, there is another dimension to this concept. There are two ways in which software evolves — one is by a change in functionality and the other is by the addition of more functionality. In both cases, though, our concerns around testability remain the same. This is because when we test an interaction at a seam, what we are effectively testing is an abstraction that should hold regardless of changing implementations.
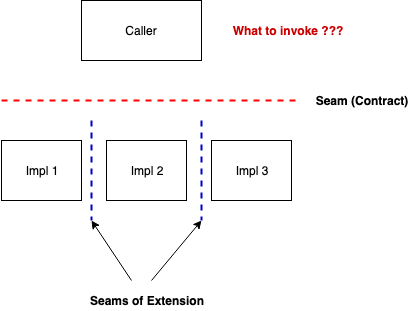
The way we could handle a change in functionality seems simple enough — modify the called side of the seam and make sure that all tests work after the change. Makes sense. How do we then add more functionality or multiple flavours of a given functionality? Changing the current implementation violates the open-closed principle of object-oriented programming and can surely lead to breaking code (even if inadvertently). The safest thing would be if could write some new code for this functionality and somehow invoke it with no changes to the existing code.
But how to do this?
I like to introduce new functionality by writing multiple implementations of the same interface on the called side of the seam. This introduces boundaries orthogonal to the earlier boundary. However, these are very different from what we were talking about before. These act more like isolation chambers or silos — there is no interaction across these, stuff on one side isn’t even aware that there are others like itself on the other side, and we can keep adding more of these, thereby continuously widening the variety of functionality offered. So to add new functionality, we just add one more implementation and stick it between the existing ones. There are our seams of extension.
However, now the caller has a problem. How should it invoke one or more of the many implementations available without changing a lot of code?
Enter Resource Locator (aka Service Locator).
We introduce a resource locator to which all implementations register itself, and we expose this to the caller instead of having him bind directly to the interface (via dependency injection etc). The resource locator now allows the caller to get access to “named” instances of the implementation (names being unique) and hence putting the caller in control of what code to invoke. The locator thus acts a bridge across the seam, allowing the caller the choice of picking the appropriate implementation out of a multitude of them. Once the name instance is return by the locator, the caller can invoke it in a similar manner as before, and we should not see any behavioural difference.
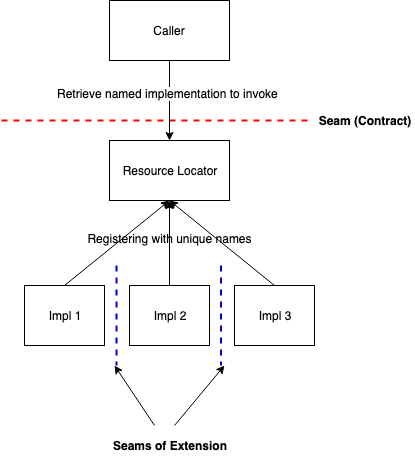
The overall effect this has on the code structure is that we can continue to add more and more functionality to our code without having to modify existing code. It also keeps intact the contract between caller and callee, so that the testability across the seam is preserved. In fact, mocking code for testing purposes becomes even easier since now there is a central access point (the resource locator) that can be manipulated to give whatever implementation is needed for testing.
There is a change in the nature of the coupling as well — the caller was previously unaware of the implementation on the other side of the seam, but now it has to ask for some specific implementation. i.e. it is directly aware that there are multiple available flavours to choose from. This awareness is not always desirable, hence this kind of design should only be used for scenarios where dynamic conditions on the calling side dictate what implementation to use, and hence we cannot bind the implementation to the caller at compile time. It is also useful when building code superstructures that require multiple implementations of the same interface to be chained by some framework code (request filters in web servers are a good example of this). The resource locator+seams combinations allow us to write more and more implementations and adding them to the chain by adding their names to some configuration that the framework can read and process.
Read Now : How continuous refactoring can help your team and codebase.
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership