What is self-documenting code?
I love documenting code and systems. Many don’t. A major argument against documents is that they get outdated as the system evolves. And the faster a system evolves, the faster its documentation gets outdated. Ironically, this is the very type of system which needs the most up-to-date documentation!
An argument is often made, therefore, for self-documenting code. This is ostensibly the kind of code that doesn’t need separate documentation because it is designed and implemented in such a way as to be self-explanatory to the reader.
How does anyone reading a codebase understand it? First, they need to know what the code is “supposed to do”. Then they can graduate to figuring out how it does that. And this is where the problem of self-documenting code lies. Because reading code is essentially reading the how. “Query some things from a database table and process them into a map, match them against some other things from some other table, and return everything that does not match as a list”. Well-written code makes it simple to understand how it is doing something. But it doesn’t tell the reader why it is doing what it is doing. And hence the reader remains confused and documentation becomes necessary to understand the intent behind the system design.
So what kind of code would reveal, even in some limited way, why it does things the way it does them?
I want to talk about the only way (IMO) code can explain itself to readers and hence become self-documenting. Let’s discuss the model underlying the code.
Becoming self-documenting
Before code comes the conceptual model that the code is the physical manifestation of. This is the mental model of the problem and the solution. This may be the domain model or another specific way of representing the programmer’s thought process and how it will achieve a programmatic solution to the problem at hand.
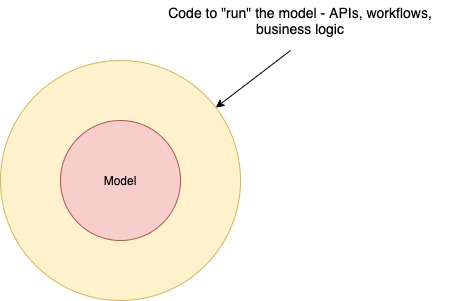
The model is the core of low-level system design. It defines the things that we are working with, what their nature is, and what role they play in solving the problem at hand. The model must be developed first before any other aspects of the low-level design like APIs, data stores, data flows can be determined. These are physical forms of the things conceptualized in the model – ways to make the model “run”. The model itself is the why, and the code is the how.
The only way to make the code self-documenting is to make the code reveal the model underlying it.
This is why the only way to make the code self-documenting is to make the code reveal the model underlying it. Code that highlights the core model instead of hiding it in implementation details builds a narrative that is much more accessible than trying to infer the meaning of some lines in code. The lines can always be interpreted, but the model made evident in well-written code sets the context under which those lines of code make sense.
Let’s take an oversimplified version of Airbnb booking. In the object-oriented, REST-ful world, the code to update a booking might look something like this. (See this gist if you have disabled JS)
This type of generic update code is fairly common. To me, this doesn’t explain why things are happening the way they are happening. Did we miss any cases? While this code can be refactored to a much cleaner form, but it does not reveal why things are happening in this way.
Let’s consider an alternative (See this gist if you have disabled JS).
Or perhaps this (See this gist if you have disabled JS).
What is the difference?
Looking at these examples makes it obvious how we can write code that makes the conceptual model explicit and hence reduce the cognitive load on the reader. The way to do this is via abstractions. All code is likely to have some amount of abstractions, but not all abstractions surface the thought process behind the code. Often developers use the model abstractions only as data carriers without imbuing them with any behavioural or semantic significance. This is the case in the first example of the generic update API. The Booking abstraction merely carries the data, all meaning is encapsulated in the if-else conditions.
Model-Driven code, on the other hand, uses model abstractions to represent the core elements and uses them as the building blocks of all other interactions in the system. They are the heart of the system and all other code only manipulates them in ways defined and controlled by the model itself. This is the case in both the second and the third examples.
It is not the case that the code in the first example does not have a model underlying it. Much like it is not possible to have “no design” (there is always design, even if inadvertent and poor), it is not possible to have “no model”. The solution sitting in the developer’s head is the model. The first example just chooses to obscure it while the latter two make efforts to make it clear.
I hope this has made clear the benefits of explicitly using a conceptual model, and building the system around it. This won’t make the system (especially a large system) automatically self-evident, but it does go a long way in that direction.
Read Next: A comprehensive look at turbocharging your software delivery pipeline
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership



3 thoughts on “How to write self-documenting code”