tl;dr : Side-step framework wars by defining the implementation and operations standards for your services. Then permit any tools which conform to this standard. The standard IS the service framework, not the technology in which it is implemented.

A lot of this article is inspired by my experiences at Myntra and D.E. Shaw and by the numerous articles and talks from engineers at Netflix.
Spring Boot recently became the Java development framework of choice at Netflix. This comes after years of the OSS community embedding bits of Netflix OSS like Hystrix, Eureka into frameworks like Spring. Internally, however, Netflix used home-grown frameworks to build their services.
A similar situation exists at many companies large enough to have many services and many teams. They want standardization of development, deployment, and monitoring styles. One of the easiest ways of achieving this is by adopting a service template or service framework.
What is a service framework
A service framework is exactly what it says it is — a template/blueprint for writing new services. The template gives out-of-the-box scaffolding and tools which facilitate rapid application development by providing what may be thought of as a “paved road”. This allows developers to focus only on writing their business logic and saves them the bother of how to structure the applications for build and deployment, or how to integrate against the company’s request tracing system.
Despite the emergence of multiple open-source service templates (Spring Boot, Play! framework, RestEasy…), companies often end up implementing their own because they want just a little bit of customization and it’s easier to roll your own (in the short term) instead of modifying something open source. The problem with this approach starts when teams want to try out some other framework or a different programming language. Now we are stuck with teams publishing metrics or other telemetry in their own way, or not being able to use the build and release systems and building their own etc. To counter this behaviour, “architecture committees” start coming out with lists of accepted technologies, explicitly whitelisting what can be used. This then annoys developers who want to play around with their favourite tools.

We want our development teams to use the best tools/frameworks/language for their work. To achieve a certain basic amount of consistency and standardization in such a poly-everything world, how do we pick the one “best” framework? How do we get the best of both worlds — standardization of tools as well the ability to experiment with technologies?
Standards over Frameworks
The answer lies not in the choice of frameworks but in imposing constraints around the output generated by their use. I argue that as long as we can define and enforce certain guidelines around behaviour of the system (basic internal structure, deployment, observability), it doesn’t matter what framework or technology is being used to build systems. If defined just tight enough, not only can these guidelines unlock technology governance and experimentation in the short term, they can also drive technology consensus in the long term.
In essence, we want the standard to be the service framework, not the technology in which it is implemented.
Defining a standard
I believe that before we start debating template choices and doing feature comparisons, it is important that an organization define the basic characteristics of an application, regardless of the language or framework it is built-in. These characteristics are the minimum set of guidelines that an application should adhere to so that systems look sort of homogenous when viewed at org-level, team level, or service level. The guidelines could include mandates around:
- Code bootstrapping and structure.
- Integration with application platform components like log aggregation, service discovery, CI/CD etc.
- Published telemetry.
These guidelines are the minimum feature-set that any service template used in the organization needs to support. The constraints around experimentation are now set, and only this set of rules has to be adhered to. Conversely, this standard, no matter how minimal, MUST be followed. This makes using new frameworks frivolously an expensive proposition and should add the requisite friction and discipline over the long term.
Pieces of the puzzle
A service framework consists of three major parts:
- The service scaffolding defines the overall structure of the code and deployables.
- Utilities (middleware etc) to integrate against application platform.
- Utilities to integrate with the framework/protocol being used (e.g. Servlet filter and interceptors, HTTP clients).
As should be clear, the more evolved a company’s application/devops infrastructure is, the wider the template definition will be, and the more the work needed to use new technologies. This is because more utilities are now needed to satisfy #2 above.
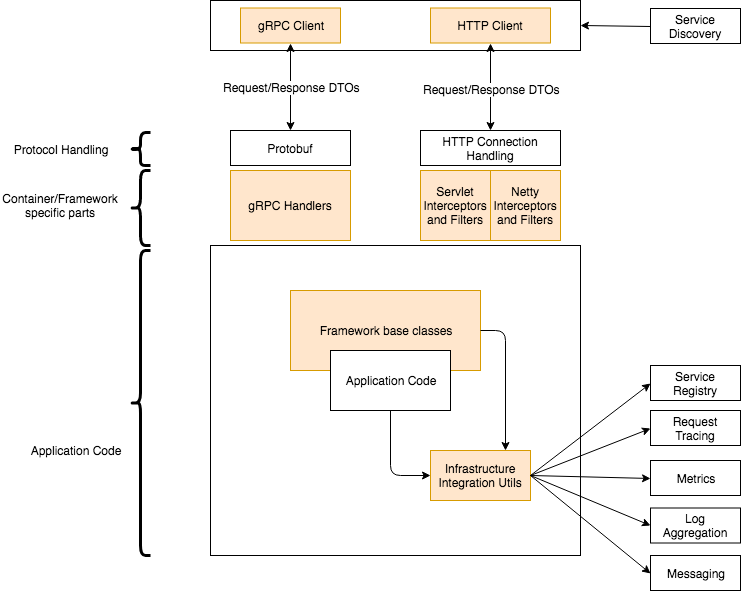
What follows is my opinion of a basic service template definition. I have put only a few things to set the stage. More rules can be added on a case-by-case basis.
Application Bootstrapping
- Developers should be able to start a new service with nearly no work: Either via a CLI-based bootstrap tool, via maven’s pom inheritance (similar to Spring Boot), or some other mechanism. Forking a skeleton service and then manually changing all configurations (like application name, deployment paths etc) is the worst way of doing this.
- The bootstrapped service should immediately deploy and run locally.
- It should be structurally ready for deployment via the CI/CD pipeline.
Application Structure
The overall application structure should be as follows.
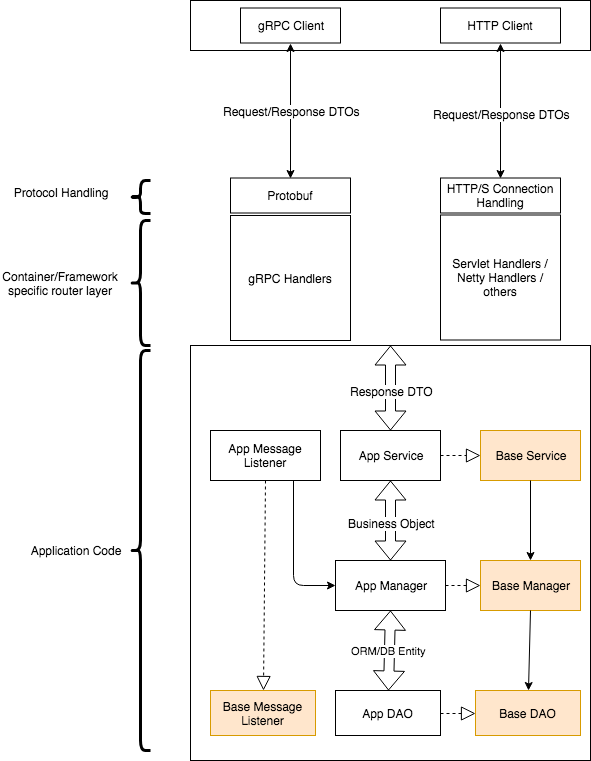
- Service layer: This is the first layer of application code in the synchronous call path and defines the semantics for the respective API mechanism.
- Message Listener layer: This is the asynchronous access path and equivalent to the service layer in that sense.
- Manager layer: This is the business logic layer and the place where most of the application code would go.
- DAO Layer: This is the data access layer.
All layers are seeded by default (Base*) implementations which provide sensible defaults for CRUD operations.
Application Integrations
- Separate utilities should be provided for integration with each piece of applications infrastructure. They should be separate so that they can be included individually as per need and not all at once as a big package.
- Utilities should encapsulate the standards defined by each infrastructure component and best practices around them.
- The utilities should be baked into the Base* structural classes as required by the minimal standard defined below so that everyone extending those classes has the integration behaviour by default.
- All integration utilities should be integrated with a common profiling utility so that they too, publish a set of useful metrics out of the box.
At the very least, utilities should be provided for synchronous and asynchronous invocation of other services and for ad-hoc instrumentation of code.
Service invoking component
- Shouldn’t abstract the details of the remote API like protocol, path etc. The details of the target service should be visible to the caller to be able to configure the interactions effectively.
- Should abstract the user from the service discovery mechanism (DNS and/or central load balancer also counts as service discovery).
- Must provide configurable connection pooling and timeout configurations to invoke remote service.
- Must provide a configurable circuit breaker to safeguard the user in case of remote service failure.
- Must propagate/generate request correlation id via the standard mechanism (header/payload etc).
Message publishing component
- Shouldn’t abstract the details of the messaging system like protocol, path etc. The details of the message broker should be visible to the application to be able to configure the interactions effectively.
- Should abstract the user from the service discovery mechanism (DNS and/or central load balancer also counts as service discovery) used for discovering the message broker.
- Must provide configurable connection pooling and timeout configurations to publish to a message broker.
- Must provide a configurable circuit breaker to safeguard the user in case of message broker failure.
- Must propagate/generate request correlation id via the standard mechanism (header/message properties etc).
Instrumentation Utility
- This is the core component using which all instrumentation is published.It integrates with the metrics management system of choice and with the prescribed standards.
- It should be able to publish counts and times.
- Instrumentation failure should not cause application failure.
- This component applies no data aggregation sampling. That is done by the metrics system.
Other useful platform components
Beyond these basics, some utilities that would be very useful to have baked into your service would be:
- Service Discovery
- Authentication and Authorization
- Distributed request tracing
- Rate Limiting
- Log Aggregation
As you build and evolve these foundational capabilities, simply upgrading your integration utilities via template version upgrades can keep the developers at the cutting edge of the platform and facilitate adoption of best practices.
Application Deployment
- Application deployment should observe the 12-factor principles.
- The deployment process for test environment and for production should be the same.
- Only difference should be the configuration.CI/CD pipeline should identify certified artefacts and only promote them to production.
- Artefact management should be done as described by the CI/CD system.
- Packaged application structure should comply with the demands of the CI/CD system.
Application Telemetry
The following data points should be recorded by the service template out of the box. Message Listener and Service layers should have largely identical telemetry behaviour since both are access gateways for the application.
Service Layer
- Request count per API
- Response time per API (sampling, avg, 90p, 99p etc will be defined and calculated by the monitoring infra)
- Response code counts per API (e.g. counts of 2xx, 3xx, 4xx, and 5xx responses for an HTTP based API).
Service invoking component
- Invocation count per API
- Observed response time per API.
- Observed response codes per API(e.g. counts of 2xx, 3xx, 4xx, and 5xx responses for an HTTP based API).
Message Listener Layer
- Processing count per message type
- Processing time per message type (sampling, avg, 90p, 99p etc will be defined and calculated by the monitoring infra).
- Response code (processing output) counts per message type (e.g. count of success/thrown exception code in a java application).
Message Producer Component
- Published message count per message type.
DAO Layer
- Count of DB queries per query type (SELECT, INSERT,UPDATE,DELETE)
- Time taken for queries per query type (SELECT, INSERT,UPDATE,DELETE).
Conclusion
The above rules should offer a good starting point for building a simple service in a basic infrastructure setup. Note that I have not mandated too many platform component beyond a monitoring system. A basic statsd setup can suffice an organization for a long time for this.If we follow the general rules laid out above, we should be able to come up with an increasingly broad but effective requirements for technology adoption. This will definitely shed more light on the path of adopting a service template which can drastically improve developer productivity and promote adoption of tools and best practices in one go.
Let the framework wars begin !!!
Read Next : Code review guidelines for distributed systems
If you liked this, subscribe to my weekly newsletter It Depends to read about software engineering and technical leadership